GraphQL
GraphQL is a query language and server-side runtime for APIs that prioritizes giving clients exactly the data they request and no more. It was developed by Facebook and later open-sourced in 2015.
GraphQL is designed to make APIs fast, flexible, and developer-friendly. Additionally, GraphQL gives API maintainers the flexibility to add or deprecate fields without impacting existing queries. Developers can build APIs with whatever methods they prefer, and the GraphQL specification will ensure they function in predictable ways to clients.
In GraphQL, the fundamental unit is a query.
Concepts
Let’s briefly discuss some key concepts in GraphQL:
Schema
A GraphQL schema describes the functionality clients can utilize once they connect to the GraphQL server.
Queries
A query is a request made by the client. It can consist of fields and arguments for the query. The operation type of a query can also be a mutation which provides a way to modify server-side data.
Resolvers
Resolver is a collection of functions that generate responses for a GraphQL query. In simple terms, a resolver acts as a GraphQL query handler.
Advantages
Let’s discuss some advantages of GraphQL:
- Eliminates over-fetching of data.
- Strongly defined schema.
- Code generation support.
- Payload optimization.
Disadvantages
Let’s discuss some disadvantages of GraphQL:
- Shifts complexity to server-side.
- Caching becomes hard.
- Versioning is ambiguous.
- n+1 query problem
Use cases
GraphQL proves to be essential in the following scenarios:
- Reducing app bandwidth usage as we can query multiple resources in a single query.
- Rapid prototyping for complex systems.
- When we are working with a graph-like data model.
Example
Here’s a GraphQL schema that defines a User type and a Query type.
type Query {
getUser: User
}
type User {
id: ID
name: String
city: String
state: String
}Using the above schema, the client can request the required fields easily without having to fetch the entire resource or guess what the API might return.
{
getUser {
id
name
city
}
}This will give the following response to the client.
{
"getUser": {
"id": 123,
"name": "Karan",
"city": "San Francisco"
}
}Learn more about GraphQL at graphql.org.
gRPC
gRPC is a modern open-source high-performance Remote Procedure Call (RPC) framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking, authentication and much more.
Concepts
Let’s discuss some key concepts of gRPC.
Protocol buffers
Protocol buffers provide a language and platform-neutral extensible mechanism for serializing structured data in a forward and backward-compatible way. It’s like JSON, except it’s smaller and faster, and it generates native language bindings.
Service definition
Like many RPC systems, gRPC is based on the idea of defining a service and specifying the methods that can be called remotely with their parameters and return types. gRPC uses protocol buffers as the Interface Definition Language (IDL) for describing both the service interface and the structure of the payload messages.
Advantages
Let’s discuss some disadvantages of gRPC:
- Lightweight and efficient.
- High performance.
- Built-in code generation support.
- Bi-directional streaming.
Disadvantages
Let’s discuss some disadvantages of gRPC:
- Relatively new compared to REST and GraphQL.
- Limited browser support.
- Steeper learning curve.
- Not human readable.
Use cases
Below are some good use cases for gRPC:
- Real-time communication via bi-directional streaming.
- Efficient inter-service communication in microservices.
- Low latency and high throughput communication.
- Polyglot environments.
Example
Here’s a basic example of a gRPC service defined in a *.proto file. Using this definition, we can easily code generate the HelloService service in the programming language of our choice.
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string greeting = 1;
}
message HelloResponse {
string reply = 1;
}HTTP2 or HTTP3
Source: gRPC cornerstone: HTTP2 or HTTP3
How to correlate streams?
var grpcTracing = GrpcTracing.create(rpcTracing);
var channel = ManagedChannelBuilder
.forTarget("mint:8089")
.intercept(grpcTracing.newClilentInterceptor())
.build();Binary logs
Machine-readable
var binaryLog = BinaryLogs.createBinaryLog();
var channelWithBinaryLogs = binaryLog.wrapChannel(channel);
var server = ServerBuilder
.forPort(port)
.addService(...)
.setBinaryLog(binaryLog)
.build();gRPC performance
Limitation: max concurrent streams. By default, it can be as low as 100.
We can create a dedicated channel for high load channel.
Pool of channels:
- use GAX Java ChannelPool
- or pool yourself
gRPC streaming: keep-alive
var channel = ManagedChannelBuilder
.forTarget("mint:8089")
.idleTimeout(1, MINUTES)
.build();gRPC streaming: caveats
- idle connections
- load-balancing
- deadlines
Don’t use to optimize performance, use to optimize your app.
Why do we need HTTP3?
TCP has a built-in loss recovery mechanism if a sender doesn’t receive an acknowledgement and it will just resent the same packet again.
TCP guarantee in order delivery and TCP is unaware of HTTP2 streams ⇒ all streams after the lost packet are delayed and are resent once again.
If the network is bad, it amplifies packet loss and it makes performance worse.
QUIC on top of UDP and re-implent TCP-like properties.
HTTP2 vs HTTP3
+-------+
| | connections
| HTTP2 | streams
| | frames
+-------+
| | loss recovery
| TCP | flow control
| | packets
+-------+
| IP |
+-------+
+-------+
| | connections
| HTTP3 | frames
+-------+
| | connections
| | streams
| QUIC | frames
| | loss recovery
| | flow control
| | packets
+-------+
| UDP | packets
+-------+
| IP |
+-------+
- QUIC is secured by default.
- connection migration
- HTTP: IPs + port quadruplet, e.g. 10.86.128.132:41210
- QUIC: connection ID, e.g. bbf4f6198293…
HTTP3:
- presevers HTTP* semantics
- delegates to QUIC
- stream lifecycle
- multiplexing
- flow control
gRPC over HTTP3:
- faster connection negotation
- no head-of-line blocking
- connection transition between networks
UDP tradeoffs*
- firewalls
- routing
- replay attacks
REST vs GraphQL vs gRPC
Now that we know how these API designing techniques work, let’s compare them based on the following parameters:
- Will it cause tight coupling?
- How chatty (distinct API calls to get needed information) are the APIs?
- What’s the performance like?
- How complex is it to integrate?
- How well does the caching work?
- Built-in tooling and code generation?
- What’s API discoverability like?
- How easy is it to version APIs?
| Type | Coupling | Chattiness | Performance | Complexity | Caching | Codegen | Discoverability | Versioning |
|---|---|---|---|---|---|---|---|---|
| REST | Low | High | Good | Medium | Great | Bad | Good | Easy |
| GraphQL | Medium | Low | Good | High | Custom | Good | Good | Custom |
| gRPC | High | Medium | Great | Low | Custom | Great | Bad | Hard |
Which API technology is better?
Well, the answer is none of them. There is no silver bullet as each of these technologies has its own advantages and disadvantages. Users only care about using our APIs in a consistent way, so make sure to focus on your domain and requirements when designing your API.
Long polling, WebSockets, Server-Sent Events (SSE)
Web applications were initially developed around a client-server model, where the web client is always the initiator of transactions like requesting data from the server. Thus, there was no mechanism for the server to independently send, or push, data to the client without the client first making a request. Let’s discuss some approaches to overcome this problem.
Long polling
HTTP Long polling is a technique used to push information to a client as soon as possible from the server. As a result, the server does not have to wait for the client to send a request.
In Long polling, the server does not close the connection once it receives a request from the client. Instead, the server responds only if any new message is available or a timeout threshold is reached.
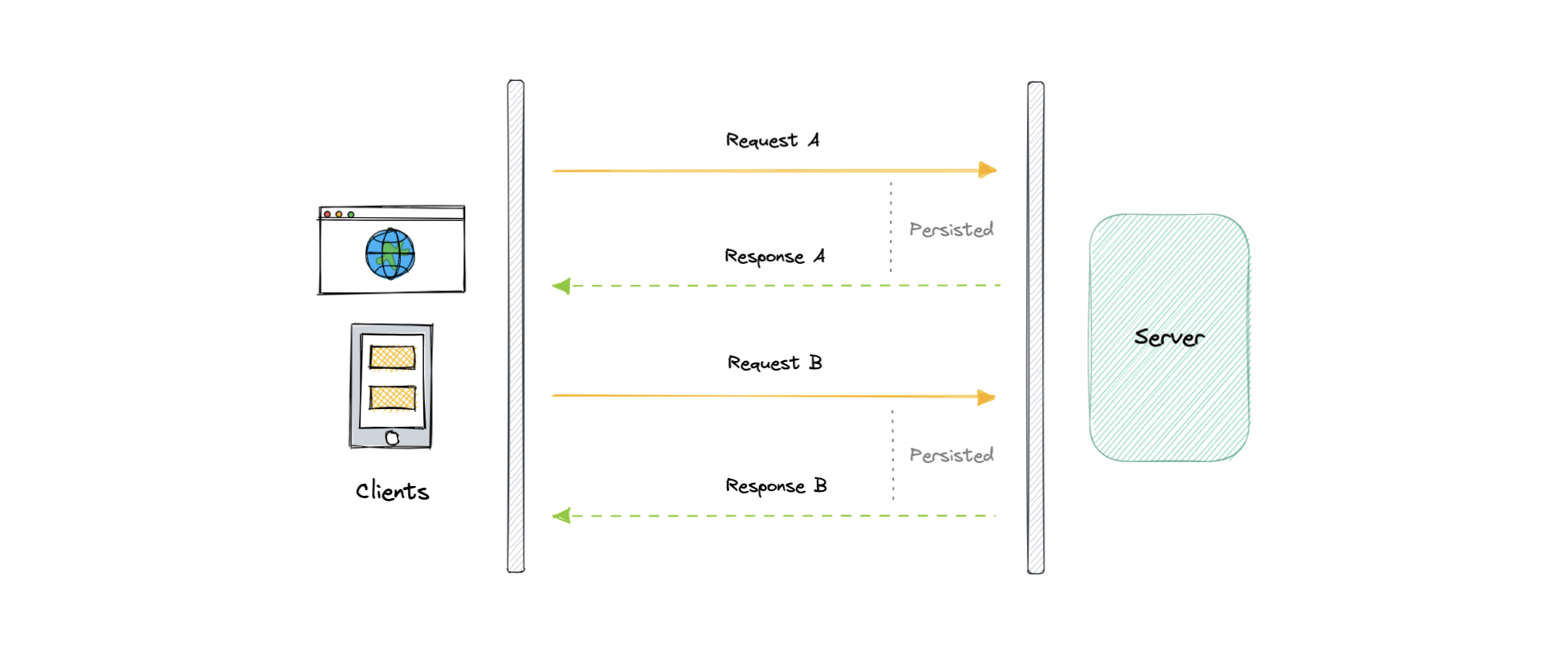
Once the client receives a response, it immediately sends a new request to the server to have a new pending connection to send data to the client, and the operation is repeated. With this approach, the server emulates a real-time server push feature.
Working
Let’s understand how long polling works:
- The client makes an initial request and waits for a response.
- The server receives the request and delays sending anything until an update is available.
- Once an update is available, the response is sent to the client.
- The client receives the response and makes a new request immediately or after some defined interval to establish a connection again.
Advantages
Here are some advantages of long polling:
- Easy to implement, good for small-scale projects.
- Nearly universally supported.
Disadvantages
A major downside of long polling is that it is usually not scalable. Below are some of the other reasons:
- Creates a new connection each time, which can be intensive on the server.
- Reliable message ordering can be an issue for multiple requests.
- Increased latency as the server needs to wait for a new request.
WebSockets
WebSocket provides full-duplex communication channels over a single TCP connection. It is a persistent connection between a client and a server that both parties can use to start sending data at any time.
The client establishes a WebSocket connection through a process known as the WebSocket handshake. If the process succeeds, then the server and client can exchange data in both directions at any time. The WebSocket protocol enables the communication between a client and a server with lower overheads, facilitating real-time data transfer from and to the server.
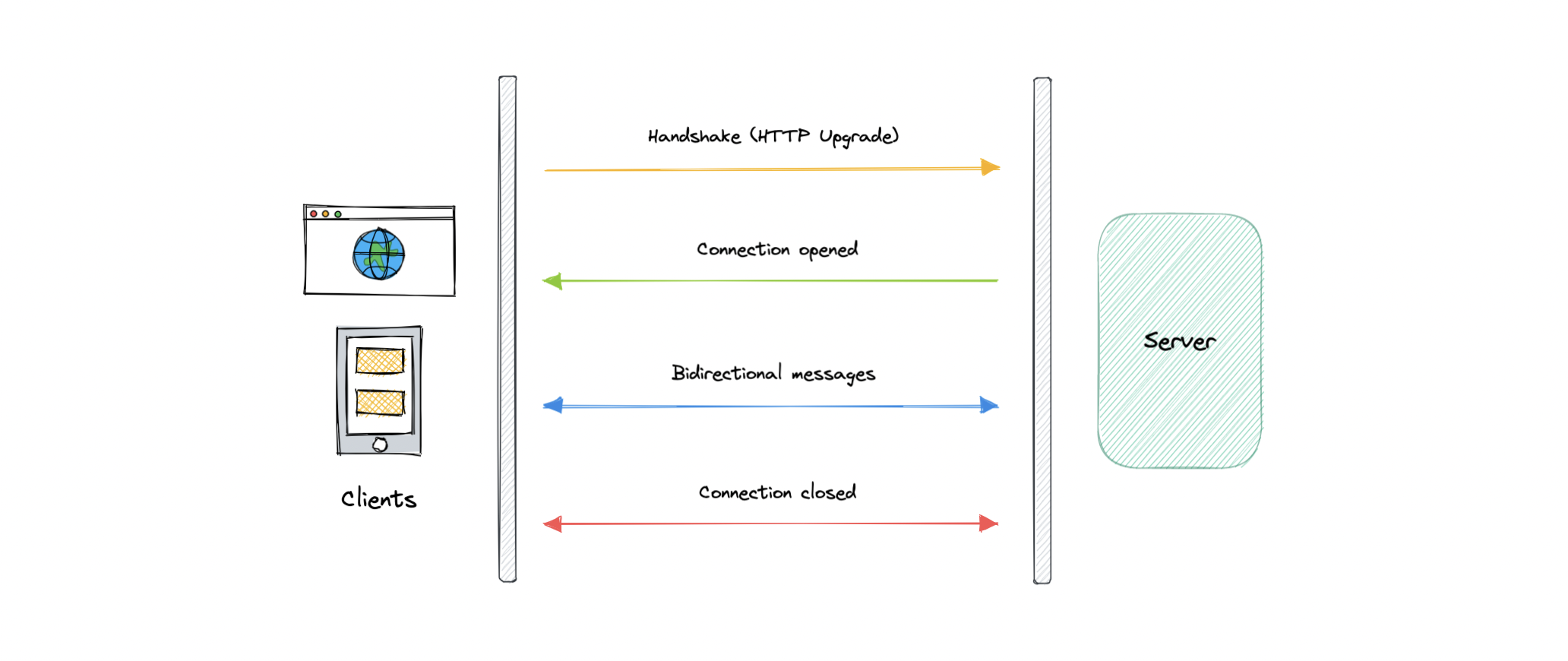
This is made possible by providing a standardized way for the server to send content to the client without being asked and allowing for messages to be passed back and forth while keeping the connection open.
Working
Let’s understand how WebSockets work:
- The client initiates a WebSocket handshake process by sending a request.
- The request also contains an HTTP Upgrade header that allows the request to switch to the WebSocket protocol (
ws://). - The server sends a response to the client, acknowledging the WebSocket handshake request.
- A WebSocket connection will be opened once the client receives a successful handshake response.
- Now the client and server can start sending data in both directions allowing real-time communication.
- The connection is closed once the server or the client decides to close the connection.
Advantages
Below are some advantages of WebSockets:
- Full-duplex asynchronous messaging.
- Better origin-based security model.
- Lightweight for both client and server.
Disadvantages
Let’s discuss some disadvantages of WebSockets:
- Terminated connections aren’t automatically recovered.
- Older browsers don’t support WebSockets (becoming less relevant).
Server-Sent Events (SSE)
Server-Sent Events (SSE) is a way of establishing long-term communication between client and server that enables the server to proactively push data to the client.
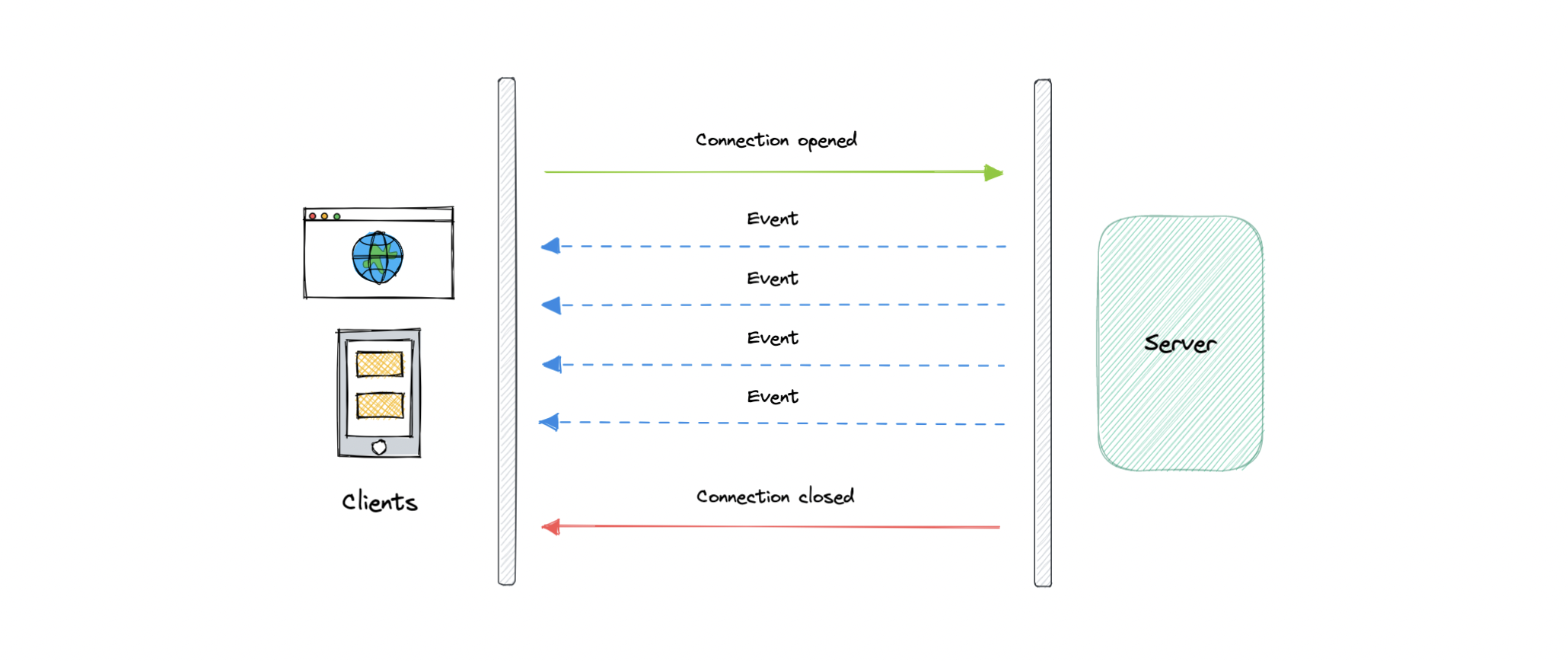
It is unidirectional, meaning once the client sends the request it can only receive the responses without the ability to send new requests over the same connection.
Working
Let’s understand how server-sent events work:
- The client makes a request to the server.
- The connection between client and server is established and it remains open.
- The server sends responses or events to the client when new data is available.
Advantages
- Simple to implement and use for both client and server.
- Supported by most browsers.
- No trouble with firewalls.
Disadvantages
- Unidirectional nature can be limiting.
- Limitation for the maximum number of open connections.
- Does not support binary data.