composable services
Abstract
A composable service is:
- Is stateless and reentrant
- Implements a domain-bounded context
- Is discoverable
- Is reactive
- Uses self-contained messages
- Uses a single service class for entity access
Composable services refer to a software architectural pattern that emphasizes the construction and integration of modular, independent services to build complex applications or systems. With this approach, services are designed to be self-contained, loosely coupled, and independently deployable components that expose well-defined interfaces.
If that sounds a lot like microservices — that’s because it is. Many of the issues and problems that have plagued the development and use of microservices can be blamed upon a failure to pay sufficient attention to microservice composability — not upon the microservices pattern itself.
The composable service pattern is based upon composing applications from self-contained, reusable services — each service focused on a specific functional or business capability so that it can be developed, deployed, and scaled independently.
These services communicate with each other through well-defined request or event messages, enabling them to work together seamlessly within or across processes.
What Makes a Service Composable?
To be considered composable, a microservice should have these characteristics:
- Is stateless and reentrant: A service should be stateless and capable of processing a single request or event message with a single thread, optimizing its efficiency. It must be fully reentrant so that it can process multiple requests or events concurrently.
- Implements a domain-bounded context: Each service should have a clear domain scope and focus on a specific functional or business capability. Well-defined domain scope enhances independent deployability and honors ownership and responsibility boundaries.
- Is discoverable: Services need to be discoverable by the message orchestrators that deliver request and event messages. They should be accessible through any federated orchestrator on the network. Service discoverability assists in the implementation of self-configuration, failover, and load balancing.
- Is reactive: Services should react to incoming request or event messages by executing logic, sending messages, or publishing events. They may also read from and write to persistent storage if they are persistent services. Reactive services emphasize responsiveness, scalability, resilience, and message-driven communication.
- Uses self-contained messages: All the information required by the service to process a message should be present in the incoming message itself or in a persistent data store. Messages should be self-describing and not require the added complexity of a separate schema management system. Self-contained messages better support service autonomy, loose coupling, and version management.
- Uses a single service class for entity access: Access to persistent data entities should be through a single service class dedicated to that specific entity class. A single service class for a data entity enhances code organization, reusability, maintainability, and testability.
The term database is sometimes misused to refer to a persistent data entity. That results in an pointless and cumbersome constraint.
Message Orchestration
A message orchestrator is software that facilitates passing messages between software components. It accepts messages in a format understood by the sender and delivers messages in a format understood by the receiver.
Orchestrators can intelligently route messages synchronously to a single recipient as a request with an expected response — or asynchronously to subscribers via a message queue. Federated orchestrators share the locations of all their registered service components among themselves.
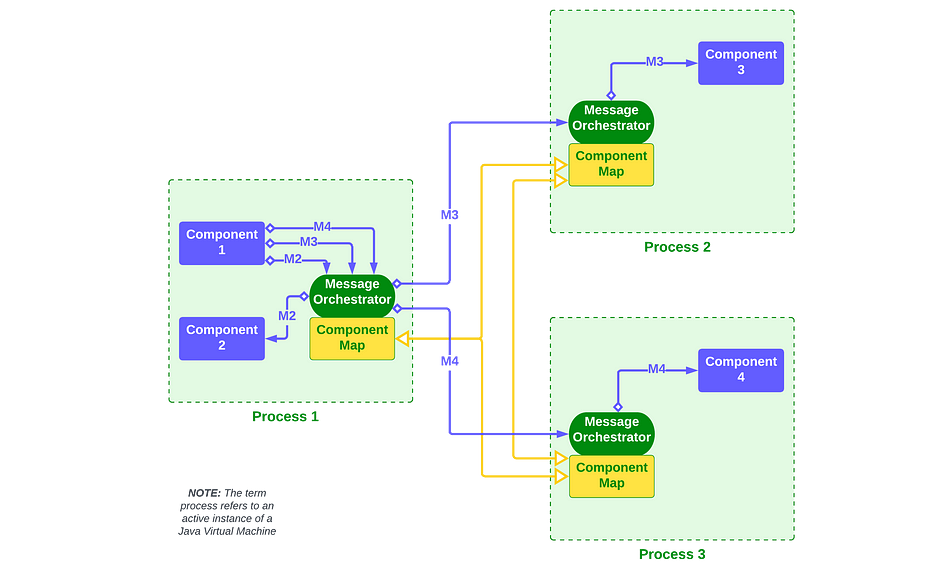
Federated Message Orchestrators
A message can be delivered over a network — but is delivered as a method call if both the sender and receiver are within the same runtime process.
In the example above, messages M2 thru M4 originate from Component 1 and are delivered to the target components (2, 3, and 4). The maps of component addresses are automatically shared among orchestrators.
The Vertical Slice
Aggregates of composable services can be organized as vertical slices, where we can implement _domain partitionin_g — so we can break things out in terms of application domain knowledge and domain-bounded contexts.
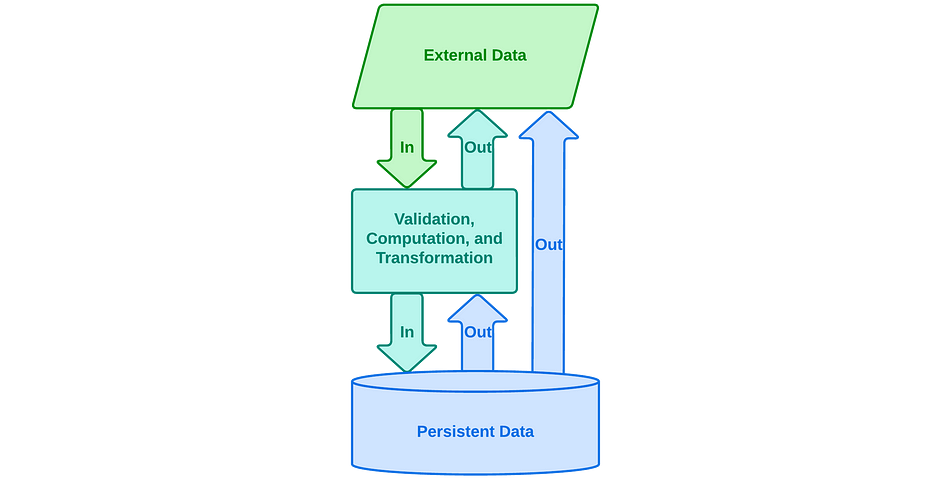
Vertical Slice of Application Functionality
The vertical slice is a pattern that repeats itself throughout most application features, and cuts a slice through the layers, from external data to persistent data. External data comes in from a UI, an electronic device, an event queue, or another application.
A vertical slice represents a logical, but not necessarily physical layering of a discrete application behavior and the communications between those layers. It provides a reasonable starting point for decomposing an application feature into executable components and the communications required to connect them.
Vertical slices are frequently aggregated together to implement larger application features and functions, while each slice continues to maintain its individual focus and separation of concerns.
The vertical slice is a useful perspective for implementing new application functionality and for modifying or re-architecting existing functionality. It is also synergistic with modern development practices such as behavior-driven development, and domain-driven design.
The Domain-Bounded Context
The Domain-Driven Design concept of a domain-bounded context is crucial to defining individual composable services that do not conflict with services developed by different teams. In plain English, context refers to “the rules and conditions within which something occurs or exists”.
A domain is “a specified sphere of activity or knowledge”. Because we are talking about software development, it is probably a good idea to add the words ownership and responsibility as well.
How do we draw domain boundaries around a context? This is not an abstract discussion of philosophy. As software developers we must decompose large complex applications into executable components with which we can build whole software systems. If we cannot identify boundaries for usable domains, we will have a hard time building composable software.
Breaking an application down into effective and usable components is probably the most critical and the most difficult challenge in software design. We have to start somewhere, so let’s put a stake in the ground and say that:
- An application is made up of components that interact using synchronous and asynchronous messaging.
- Every application component exists within its own domain-bounded context.
- A context is made up of the data that represents it state and the logic and rules that govern that state.
- Components, and therefore contexts, can be aggregated into more complex components and contexts.
- The context of an application is the aggregate of the contexts of all its components.
The word component means “a part or element of a larger whole”. In this case, it is a part of a software system that is independently compilable and deployable, describes the state, rules, and logic of a bounded context, and exposes a programming interface through which other components may interact with it.
Breaking up a bounded context refers to dividing a large, complex domain into smaller, more manageable parts. Bounded contexts represent a boundary around a cohesive set of domain models and business rules. Breaking up a bounded context can be necessary when it becomes too large or unwieldy to reuse, maintain, understand, or evolve effectively.
Do not be afraid to break a complex domain into more atomic, reusable, and manageable sub-domains that can be aggregated to implement more complex domains. This is especially important when implementing domains that act on multiple persistent data entities.
The Power of Aggregation
In Domain-Driven Design, aggregation is a fundamental concept that helps organize and model complex business domains. An aggregate is a group of related components that are treated as a single unit. It represents a whole-and-parts relationship where a entry point component, known as the aggregate root, manipulates the other components.
The aggregate root ensures consistency and maintains the integrity of the aggregate by enforcing business rules and invariants. All interactions with the components within the aggregate are performed by messaging the aggregate root.
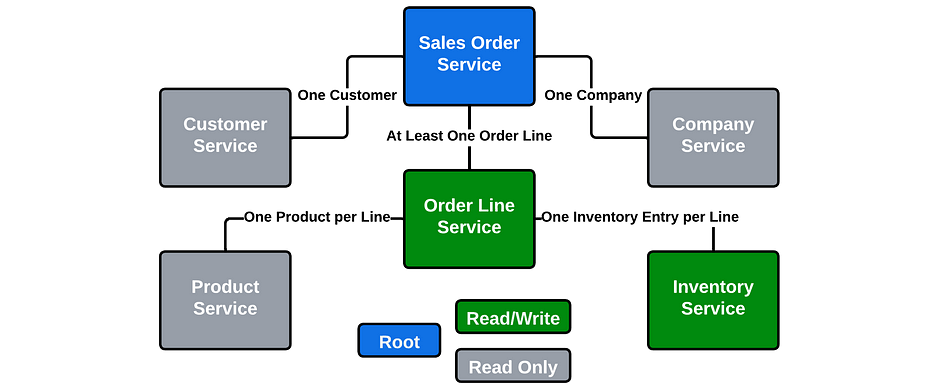
Sales Order Aggregate
Aggregates have the following characteristics:
- Consistency boundary: Aggregates define transactional consistency boundaries. They ensure that the objects within the aggregate are always in a valid and consistent state.
- Encapsulation: The internal structure and implementation details of an aggregate are hidden from the outside. Requestors can only interact with the aggregate root, maintaining a clear boundary of responsibility.
- Lifecycle management: Aggregates ensure that all objects within them are created, modified, and deleted as a whole. Changes to the aggregate are atomic and consistent.
- Business rules enforcement: Aggregates enforce business rules and invariants within their boundaries. They control the state changes and validity of the objects they contain.
By identifying and defining aggregates we can model complex business processes and ensure that the interactions and relationships between objects are well-defined and manageable. Aggregates play a crucial role in maintaining the integrity and consistency of the domain model in DDD.
In Summary
Upon its discovery by a message orchestrator, a composable service becomes a part of the application and, subject to applicable security constraints, is able to send and receive messages, publish and subscribe to events, and seamlessly join in the functionality of the application system.
An individual requestor or event publisher does not need to know the network location of any other services with which it communicates, the message orchestrator with which it has registered is responsible for that.
This decentralized structure provides resiliency and robustness. When any service cannot be reached, the request can be automatically redirected to a reachable instance of the service. It is a very cost-effective approach to building applications that are functionally rich, performant, resilient, and extensible. Try it!