redis caching data structures
Abstract
In the realm of high-performance applications, caching systems like Redis stand as guardians of speed and efficiency.
They act as intermediaries, intercepting data requests and serving up frequently accessed information with lightning-fast speed, all while shielding your primary data source from excessive load.
But how do these systems work their magic? Buckle up, as we delve into understanding Redis and its caching techniques.(Detailed architecture and Use cases (Paid))
But before that… What is actually caching and why do we even need it?
Imagine you’re walking to your own cafe(for work ofcourse!).
There is a demand for specific coffee bean ☕everyday in the morning.☀
What do you do ?
Instead of searching the whole pantry every morning, you keep a jar of instant coffee readily available for quick brews.
That’s the essence of caching:
Storing frequently used data in a readily accessible location for faster retrieval.
In the digital world, data often resides on hard drives, which are slower than your computer’s memory (RAM).
Accessing data from a hard drive is like walking to the pantry, whereas accessing data in RAM is like grabbing the instant coffee from the jar.
So caching is basically needed if you demand:
- Speed: It dramatically improves response times. Just like you get your coffee faster with instant coffee, your applications and websites load quicker with cached data.⚡⚡
- Reduced Load: Frequent database access can overload it, impacting performance. Caching reduces the burden on the database, ensuring smooth operation.🔃
- Cost-Effectiveness: By minimizing database usage, caching can lead to lower server costs, especially for high-traffic applications. 💲💲💲
While there are different types of caching. You can optimize it based on your requirements
- Browser Caching: Stores website data on your device for faster future visits.
- Application Caching: Specific applications implement their own caching mechanisms.
- Content Delivery Networks (CDNs): Distribute cached content across geographically dispersed servers for faster global access.
okay, lets get back to Redis!

Redis (“_RE_mote _DI_ctionary _S_ervice”) is an open-source key-value database server.
The most accurate description of Redis is that it’s a data structure server. This specific nature of Redis has led to much of its popularity and adoption amongst developers.
Imagine a library where the most popular books are readily available on a dedicated shelf instead of tucked away in the stacks.
That’s the key principle behind Redis - it stores frequently accessed data in memory (RAM), which is significantly faster than traditional disk-based storage.
This translates to lightning-fast data retrieval, a stark contrast to the sluggishness of accessing data from databases.
But speed isn’t everything.
Caching systems also embrace the power of key-value stores.
Think of them as digital dictionaries where each data item is associated with a unique key.
This allows for quick lookups and retrieval, eliminating the need to scan through vast amounts of data to find what you need based on below key concepts.
- Hashing: Used for mapping keys to data locations in memory. Redis employs its own hashing function (MurmurHash) for efficient key distribution and retrieval.
- Skip Lists: Used in Sorted Sets for efficiently maintaining ordered elements based on scores. Skip lists offer logarithmic time complexity for insertion, deletion, and retrieval operations.
- Pub/Sub: Leverages a publish-subscribe pattern for real-time data updates. Channels act as topics, and subscribers are notified of new messages published to relevant channels.

It boasts a diverse set of data structures that cater to various needs:
Let’s delve into each Redis data structure with some concrete examples to illustrate their use cases:
- Simple Strings types: Consider Caching frequently accessed user profiles, storing website configuration settings, or keeping track of simple counters.
Storing a user’s name under the key “username:JohnDoe” with the value “John Smith”.
- Hashes types: Storing user profiles with multiple attributes, product information with various details, or shopping cart contents with item IDs and quantities.
Storing a user’s profile information under the key “user:123” with fields like “name”, “email”, and “age”.
- Lists: Implementing task queues, managing chat message history, or creating a to-do list application.
Using a list called “todo:JohnDoe” to store tasks like “Buy groceries”, “Finish report”, and “Call mom”.
- Sets: Filtering duplicate entries, checking user membership in groups, or implementing real-time chat room member lists.
Using a set called “unique_users” to store unique user IDs for website analytics.
- Sorted Sets: Creating leaderboards for games or competitions, prioritizing tasks based on importance, or implementing real-time trending topics.
Using a sorted set called “leaderboard” to rank users based on their scores in a game, with the highest score at the top.
Additionally, it also supports:
- Redis Streams: Imagine a social media platform like Twitter using Redis Streams to process and store a high volume of tweets in real-time.
- Redis Pub/Sub: A news website could use Redis Pub/Sub to broadcast breaking news updates to all subscribed users instantly.
- Redis Lua Scripting: An e-commerce platform might use Lua scripting to conditionally update product prices based on specific criteria within Redis. This flexibility allows Redis to adapt to a wide range of use cases, from caching frequently accessed website content to powering real-time chat applications.
Remember, the choice of data structure depends on your specific needs and the type of data you’re working with.
By understanding these diverse options, you can leverage Redis to its full potential and build efficient, scalable applications.
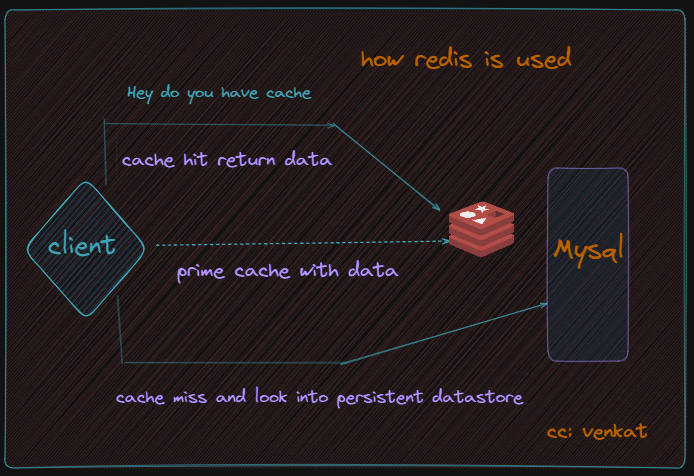
So, how does the magic happen?
- Imagine your web browser wants to display a website. It first asks Redis, “Hey, do you have the content for this page?”
- Redis acts like a super-fast librarian. It checks its “memory shelves” (RAM) to see if the requested data is there. This check happens in microseconds, much faster than searching a traditional database on a hard drive.
- If Redis finds the data (a cache hit!), it’s like finding the book right away on the shelf. It sends the data to the browser instantly, resulting in a blazing-fast page load.
- If the data isn’t in the cache (a cache miss), it’s like the book being checked out or misplaced. Redis then goes to the slower “main library” (database) to retrieve the data.
- Redis retrieves the data from the database and, like a good librarian, also adds it to its own “memory shelves” for future requests. This way, if someone else wants the same page, it’s readily available in the cache, saving another trip to the database.
- Like a library backing up its collection, Redis can optionally write the cached data to disk (RDB or AOF) in case of power outages or restarts. This ensures data isn’t lost, but it’s slower than keeping it purely in memory.
key Insights:
- Redis has various “data structures” like strings, lists, and sets, each suited for different types of information. Imagine different sections in the library for different content formats.
- Caching doesn’t have to be perfect. Sometimes, data in the cache might be slightly outdated, but the trade-off for speed is often worth it.
- Redis can also be used for real-time data processing, leaderboards, and more, not just caching. It’s a versatile tool for many data needs.
But you might think how Redis is so fast ryt ?
The blazing speed of Redis compared to traditional databases boils down to two key factors: in-memory storage and optimized data structures.
But additional to these factors its much faster because of
- Reduced I/O Operations: Accessing data in RAM bypasses disk I/O operations, eliminating bottlenecks and delays associated with hard drives.
- Single-Threaded Architecture: Unlike databases with complex multi-threaded processing, Redis uses a single-threaded model, simplifying operations and minimizing overhead.
- Event-Driven Design: Redis reacts to requests efficiently with its event-driven architecture, handling multiple clients without context switching delays.
But even with this advantages there is a few limitation to it.
-
Limited Capacity: RAM is smaller than hard drives, so Redis can’t store massive datasets.
-
Data Persistence: By default, Redis data is volatile and lost upon restarts. Persistence options (RDB/AOF) exist but come with performance trade-offs.
RDB (Snapshotting): Periodically takes snapshots of the entire dataset and stores them on disk. Offers durability but incurs performance overhead.
AOF (Append-Only File): Logs every write operation sequentially. Ensures data durability but can be slower than RDB.
Choosing the Right Caching System is a balancing act
The decision to adopt a caching system like Redis depends on several factors:
- Data Size and Access Patterns: In-memory caches excel with frequent accesses to smaller datasets.
- Consistency Requirements: Decide between eventual consistency (cache updates eventually reflect changes) or strong consistency (instantaneous cache updates).
- Fault Tolerance: Consider clustering and data persistence for high availability and data durability.
let’s discuss the various Redis deployments and their trade-offs.
We will be focusing mainly on these configurations:
- Single Redis Instance
- Redis HA
- Redis Sentinel
- Redis Cluster
Depending on your use case and scale, you can decide to use one setup or another.