open telemetry - tracing
Abstract
Le tracing, c’est génial mais souvent sous-exploité aujourd’hui dans notre industrie. Venez découvrir pourquoi vous devez mettre des traces dans vos applications.
Cet article est second article de ma série sur l’observability. Retrouvez le premier article sur les métriques ici.
C’est quoi le tracing ?
Le tracing est une technique permettant de suivre au sein d’un même service ET également entre services (donc dans un système distribué) le “parcours” d’une action. Exemple:
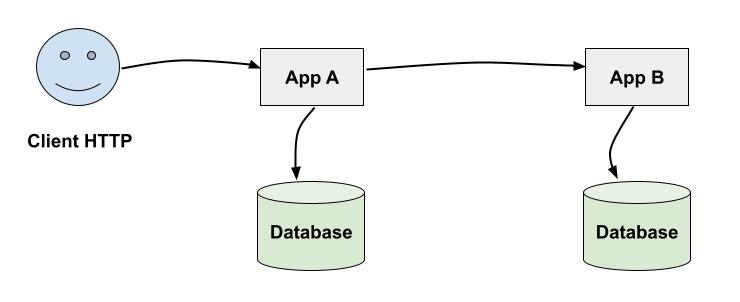
- Une client HTTP envoie une requête à une application appelée
App A App Areçoit la requete, déclenche une autre requête vers une base de données, puis envoie également une requête HTTP à une applicationApp BApp Breçoit la requête, fait également une requête à une base de données, et renvoie une réponse àApp AApp Aretourne la réponse au client initial
On voit ici qu’une action utilisateur (la requête HTTP) a déclenché de nombreuses actions côté applicatif.
Il est souvent difficile de suivre dans les systèmes d’aujourd’hui, notamment microservices, ce type d’actions. C’est là que le tracing intervient: il nous permet de suivre avec détails ce qu’il se passe sur nos systèmes.
Opentelemetry est une implémentation standard du tracing. Le fait que ce soit un standard est très important. Traditionnellement les APM (cloud type Newrelic, Datadog…) fournissaient leurs propres agents et SDK pour ce type de besoins. Avec Opentelemetry votre code applicatif n’est plus lié à un vendor particulier et donc n’est pas “lock-in”.
Si vous utilisez Opentelemetry pour les traces, vous aurez la possibilité de facilement changer de technologie de stockage (cloud ou on premise) sans changer votre application, notamment grâce à l’Opentelemetry collector qui est un composant pouvant recevoir et ensuite transférer les traces à différents systèmes
Tout un écosystème s’est développé autour d’Opentelemetry et des traces et l’outillage aujourd’hui est très bon dans tous les langages “mainstream”. Des gestionnaires de traces comme Grafana Tempo vous permettent par exemple d’avoir de très belles représentations d’une action sur un système distribué (image tiré de cet article).
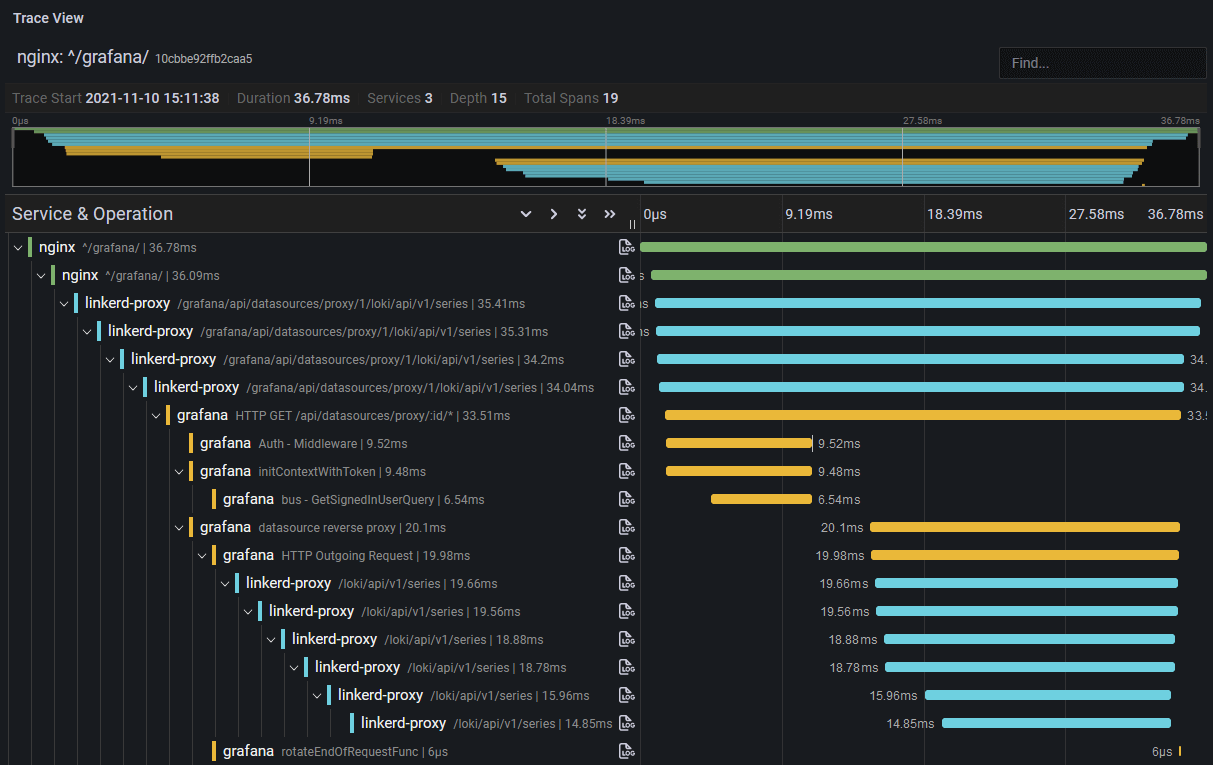
D’autres visualisations sont possibles comme des “services map” montrant sous forme de graphe les communications entre services.
Traces et Spans
On va donc générer des traces composées de spans pour suivre nos requêtes et actions. La documentation officielle d’Opentelemetry explique bien le concept que je vais résumer ici.
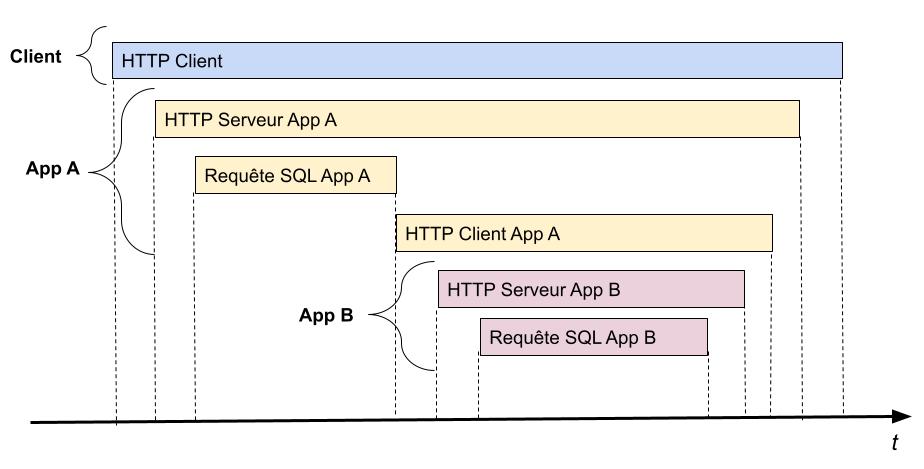
Prenons l’exemple précédent. Il va être possible avec Opentelemetry de mesurer le temps d’exécution de chaque étape du parcours de notre action. On veut donc mesurer le temps d’exécution de la requête par le client HTTP original. Puis le temps passé dans l’application A, où l’on peut mesurer le temps de traitement de la requête HTTP par le serveur, qui sera lui même composé du temps d’exécution de la requête SQL et de l’appel HTTP à l’application B. Même chose pour l’application B où l’on mesurera le temps de traitement de la requête HTTP reçue et de la requête SQL exécutée.
Voici une représentation de cela, avec le temps en abscisse:
Il serait également possible de représenter cette série d’action comme un arbre:
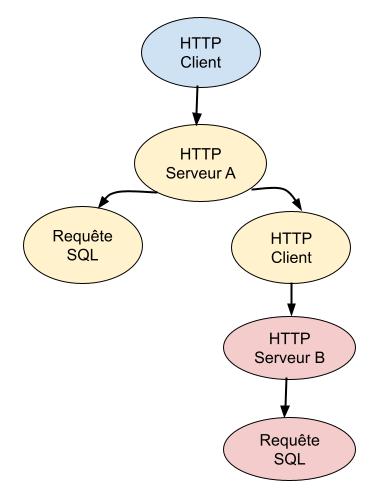
On voit ici que chaque action a comme noeud suivant l’action (ou les actions) suivante (et inversement ces actions ont comme parent l’action précédente).
On pourrait également représenter l’exécution de la toute première requête HTTP (HTTP Client) en JSON:
{
"name": "HTTP Client",
"context": {
"trace_id": "0x5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "0x5fb397be34d26b51"
},
"start_time": "2023-08-19T17:52:58.114304Z",
"end_time": "2023-08-19T17:55:98.114304Z",
"parent_id": null,
"attributes": {
"http.route": "/foo",
"http.request.method": "GET",
"http.response.status_code": 200,
"server.port": 443,
"url.full": "https://app-a.mcorbin.fr/foo"
}
}En fait, ce JSON est la représentation d’une span opentelemetry. Comme dit précédemment une trace permet de suivre l’exécution d’actions liées entre elles. Une trace est tout simplement une liste de spans partageant le même trace_id.
Dans cet exemple, ma span a une trace_id égale à 0x5b8aa5a2d2c872e8321cf37308d69df2. Elle a une également une span_id (0x5fb397be34d26b51, permettant de l’identifier de manière unique).
Ma span a également une date de début et de fin (start_time et end_time). La span démarre avant l’exécution de l’appel HTTP, et se termine lorsque la réponse est reçue. On peut comme cela déduire le temps d’exécution total ce cette action.
Vient ensuite le champ parent_id. Rappelez-vous de la représentation en arbre des actions: ici, c’est la première action à être exécutée donc la span n’a aucun parent: c’est ce qu’on appelle la root span.
Viennent ensuite les attributes dont nous allons parler dans la section suivante.
Spans et attributes
Une span avec juste un nom (comme HTTP Client) et un temps d’exécution serait inutile: il serait impossible d’en faire quelque chose et de comprendre l’action réalisée. C’est là qu’interviennent les attributes.
Dans la span représentée précédemment, les attributes seront liés à la requête HTTP réalisée: route, méthode, status de la réponse, port, url cible… cela permet de comprendre immédiatement la requête qui a été exécutée.
Représentons maintenant la span suivante de notre arbre: le serveur HTTP recevant la requête dans l’application A:
{
"name": "HTTP server",
"context": {
"trace_id": "0x5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "0x8ad397bae4d26489"
},
"parent_id": "0x5fb397be34d26b51",
"start_time": "2023-08-19T17:53:01.114304Z",
"end_time": "2023-08-19T17:55:50.114304Z",
"attributes": {
"http.route": "/foo/:id",
"http.request.method": "GET",
"http.response.status_code": 200,
"url.path": "/foo/123456",
"url.scheme": "https",
"server.port": 443,
"server.address": "app-a.mcorbin.fr",
"client.address": "10.36.1.2",
"client.port": 39874
}
}Regardons déjà les ID de trace et de span. Le trace_id est le même que la span HTTP CLient: en effet, les deux spans font partie de la même série d’action (de la même trace). Le span_id est par contre unique à la span.
Ici, le parent_id n’est pas null: il est égal à 0x5fb397be34d26b51 qui est la valeur de la span précédente (HTTP Client). Cela est logique car c’est bien cette span qui est parente dans l’arbre.
Les attributs donnent également ici des informations sur la requête HTTP reçue. On peut voir quelques similitudes avec la span HTTP Client.
Conventions de nommage
On a vu l’importance des attributs pour donner du contexte aux spans.
Dans notre exemple du début d’article on aurait par exemple une span pour la requête SQL du service A. Cette span ressemblerait probablement à quelque chose comme:
{
"name": "SQL query",
"context": {
"trace_id": "0x5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "0x1bc187ba44dc6aea"
},
"parent_id": "0x5fb397be34d26b51",
"start_time": "2023-08-19T17:53:08.114304Z",
"end_time": "2023-08-19T17:53:49.114304Z",
"attributes": {
"db.name": "users",
"db.statement": "SELECT id, email, password FROM users WHERE =$1",
"db.operation": "SELECT"
}
}
Ici les attributs seront spécifiques à SQL et nous permettent aussi de facilement identifier l’action réalisée.
Il est important de standardiser les attributs. Nous allons en effet pouvoir faire des recherches sur les traces. Cela serait très difficile si un service nommait un attribute db.statement et l’autre database.statement: il faut des conventions de nommage.
Le standard Opentelemetry fournit déjà une liste de noms et types d’attributs (let attributes sont typés) standards. Vous pouvez trouver cette liste ici.
Tous les attributs techniques “classiques” (en lien avec des technologies comme les base de données, les cloud providers, des protocoles comme HTTP ou gRPC) sont déjà standardisés. Des librairies existent également pour construire ces attributs standards (comme la lib semconv en Golang).
Il est également très important de standardiser vos attributs métiers. Avoir des attributs techniques attachés aux spans est intéressant, mais il est encore plus intéressant d’attacher du contexte métier à vos spans.
Cela peut être des attributs comme <company-name>.user.id, <company-name>.organization.id ou tout autre attribut métier important.
Rappelez vous que les traces sont intéressantes notamment pour découvrir des problèmes de performance: peut être allez-vous vous rendre comme que c’est toujours les requêtes venant d’un utilisateur spécifique qui sont lentes grâce à un attribut contenant son ID. Sans cet attribut, l’investigation du problème pourrait être beaucoup plus lente.
Resource
Il est commun dans une span d’avoir également un bloc resource contenant des attributs communs à une application:
{
"resources": {
"service.name": "App-A",
"service.version": "0.0.1"
}
}Ces attributs sont souvent utilisés par les base de données de traces pour stocker ensemble les spans d’un même service, car toutes les spans émises par une instance d’un service donné auront les mêmes ressources.
Scope
Un autre bloc présent dans une span est le bloc scope. Voici par exemple le contenu de scope pour une span émise par le package Golang otelgin, permettant d’ajouter le support d’Opentelemetry au framework Gin:
{
"scope": {
"name": "go.opentelemetry.io/contrib/instrumentation/github.com/gin-gonic/gin/otelgin",
"version": "0.42.0",
"attributes": {}
}
}Cela permet de voir que cette span a été générée par cette librairies. La documentation officielle d’Opentelemetry explique bien cela.
Status
Il est également possible d’ajouter à une span un status avec un message permettant de très rapidement filtrer les spans en erreur. Une span représentant une erreur de validation de requête HTTP pourrait avoir comme status:
{
"status": {
"message": "Invalid HTTP Body",
"status": "error"
}
}
Events, et pourquoi les traces peuvent remplacer les logs
On arrive à un concept que j’adore dans le tracing: les events.
On a étudié précédemment des exemples de spans représentant une action avec une date de début, une date de fin et des attributs.
Il est également possible d’ajouter à une span des messages arbitraires avec un timestamp fixe associé et des attributs: ce sont les events. On peut voir un event comme un log, c’est exactement le même principe.
Reprenons notre exemple de serveur HTTP recevant une requête. Il est commun d’avoir dans des handlers HTTP des logs applicatifs de ce type:
logger.Infof("received request from user %s to perform action Foo", userID)
logger.Infof("user %s is in trial mode", userID)
// traitement de la requête
logger.Infof("successfully performed action Foo for user %s", userID)Ces logs sont il est vrai de faible qualité (c’est juste pour l’exemple) mais on voit souvent ce genre de patterns avec de nombreux logs ajoutés “au cas où” et loggant toute sorte de choses en production.
Mais si vous faites du tracing, ces logs peuvent complètement disparaître:
-
L’user ID et mode peuvent être simplement attaché à la span comme un attribute
-
Des events attachés à la span peuvent remplacer les logs
Un exemple:
{
"name": "HTTP server",
"context": {
"trace_id": "0x5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "0x8ad397bae4d26489"
},
"parent_id": "0x5fb397be34d26b51",
"start_time": "2023-08-19T17:53:01.114304Z",
"end_time": "2023-08-19T17:55:50.114304Z",
"attributes": {
"user.mode": "trial",
"user.id": " 86a7d17f-ab35-4312-88ea-9414a15e450b",
"http.route": "/foo/:id",
"http.request.method": "GET",
"http.response.status_code": 200,
"url.path": "/foo/123456",
"url.scheme": "https",
"server.port": 443,
"server.address": "app-a.mcorbin.fr",
"client.address": "10.36.1.2",
"client.port": 39874
},
"events": [
{
"name": "successfully performed action Foo",
"timestamp": "2023-08-19T17:55:20.114304Z",
"attributes": {
"user.id": " 86a7d17f-ab35-4312-88ea-9414a15e450b",
}
}
]
}Comme vous pouvez le voir, un log est devenu un event attaché à ma span et le reste des attributs (user.id et user.mode). Et ça, c’est GENIAL.
Pourquoi c’est genial ? Reprécisons pourquoi le tracing est intéressant: suivre des actions entre services. Les logs sont très souvent utilisés pour ça également. Qui n’a jamais utilisé les logs pour suivre le parcours d’une requête dans une application, ou même entre applications via des recherches plus ou moins complexes ?
En ayant des attributs métiers dans mes spans ET en ajoutant des events lorsque j’ai besoin d’avoir un timestamp exact associé à un message, j’ai le meilleur des deux mondes:
- Je bénéficie de tout l’écosystème des traces pour suivre le parcours de mes actions
- Je peux, une fois ma requête identifiée, avoir facilement tous les “logs” (events) associés à cette requête car ils seront tout simplement attachés aux spans?
C’est un énorme gain de temps. Je n’ai pas à jongler entre différents outils pour essayer de trouver une information. Du moment que j’ai un ID de trace (ou que je peux le retrouver via une recherche sur un attribut), j’ai accès à toutes les informations sur cette trace (depuis tous mes services) d’une manière unifiée. Je n’ai plus à galérer à corréler des logs entre eux, ma trace et mes spans le font pour moi !
Je prévois dans le futur une fusion des outils de gestion de traces et de logs. Pourquoi garder les deux alors que les traces font déjà un boulot LARGEMENT meilleur tout en étant un format standard ?
Je pense que si je devais reconstruire un système d’information “from scratch” aujourd’hui je:
- Garderai les logs pour les erreurs et certains logs très importants (type logs “légaux” à conserver). Et encore: le SDK Opentelemetry permet d’attacher des erreurs aux spans sous forme d’events donc c’est également super d’avoir les erreurs attachées aux spans.
- Tout le reste: des traces avec des attributs et events de qualité. Je suis sûr qu’on pourrait même faire une sorte de “log level” pour les traces, ajoutant certains events à des spans en fonction d’une configuration globale, comme un logger.
Sampling
Cela me permet de rebondir sur le sujet du sampling. On entend toujours dire lorsqu’on parle des traces “conserver 100 % des traces est trop coûteux en stockage car trop de volume”, et donc qu’il faut faire du sampling (par exemple, ne conserver que 5 % des traces). Je ne pense pas que ce soit une bonne idée.
Certains outils comme Grafana Tempo ont pour objectif de pouvoir garder 100 % des traces en les stockant sur S3 pour baisser les coûts. Mais le lien entre traces et logs est aussi important.
Les logs aussi sont souvent coûteux à stocker (je vois les utilisateurs Elasticsearch sourire en lisant ça). Pourtant, des applications qui loggent comme des porcs sans que personne ne lève un sourcil ne posent aucun problème dans de nombreuses entreprises, et personne ne veut faire du sampling sur les logs car cela baisse les capacités d’investigations de problèmes.
Pourquoi ne pas voir les traces comme un remplaçant des logs et donc avec un transfert des coûts depuis les logs vers les traces ? Au final, l’information est quasiment la même, les deux sont des hashmaps clé/valeur.
Ne vous dites pas “j’aurai 40TB de traces en plus de mes 40TB de logs”, mais plutôt “j’aurai 40TB de traces mais plus que 2TB de logs, et une meilleure capacité à investiguer des problèmes”. C’est vraiment vers ça que doit pour moi se tourner l’industrie (et les gens construisant des outils de gestion de logs).
Pour aller plus loin
Il y a d’autres champs disponibles dans les spans. Les Links permettent de lier des spans entre elles même si elles font partie d’autres traces (donc d’avoir aussi des relations entre traces et non seulement entre spans d’une même trace). Le champ Kind permet d’ajouter une valeur spéficiant si l’émetteur est un client, un serveur, ou consumer de messages (d’une queue de message par exemple)…
Bref, la définition des spans est vaste et le mieux est d’explorer la documentation.
Propagators
Les traces permettent donc de suivre entre systèmes des actions. Mais comment réaliser cela quand par exemple un client envoie un requête HTTP à un serveur, ce serveur publiant ensuite un message dans une queue de message (ou Kafka par exemple) qui sera ensuité consommé par un autre service ?
Nous voulons pouvoir suivre l’action jusqu’à sa fin. C’est là que les propagators interviennent: c’est une convention pour passer des informations de tracing entre systèmes.
Le plus connu est le propagator Trace context: c’est un standard du W3C.
Dans le cas d’un client HTTP faisant un requête sur un serveur, les informations de la span courante côté client seront passées au serveur via un header HTTP appelé Traceparent, par exemple:
Traceparent: 00-0af7651916cd43dd8448eb211c80319c-00f067aa0ba902b7-01
Le format est <version>-<trace-id>-<parent-span-id>-<flags>
Le serveur récupèrera ces informations et les utilisera pour ses propres spans (notamment en mettant dans trace_id l’ID de la trace et dans parent_id l’ID de la span parente du client).
Pour de l’asynchrone, pareil: les informations de la trace seront passées dans le message et récupérées par le consommateur. Quand vous utilisez Kafka, il est courant d’utiliser les headers du protocol Kafka pour cela.
Il est très important de ne jamais “casser la chaine” du tracing ou alors le contexte est perdu, et votre trace incomplète. Cela demande une certaine discipline dans le code applicatif pour être sûr que le contexte est toujours passé entre fonctions et à chaque I/O. Si un service intermédiaire n’implémente pas le tracing et casse la chaine, c’est game over.
Générer des métriques depuis les traces ?
Pourquoi as-ton besoin de traces quand on a des métriques ? Car il n’est pas possible avec des traces brutes d’avoir une vue aggrégée du comportement d’un système.
Les traces permettent d’avoir accès aux détails sur la performance d’une requête unique: cela est impossible avec des métriques type Prometheus.
Les métriques fournissent des informations comme par error le nombre de requêtes par seconde sur un service, et du nombre d’erreur (error rate). Elles vont fournir aussi des quantiles pour mesurer la latence (p50, p99…). Et c’est sur des métriques que l’on pourra définir des SLO et calculer par exemple des choses comme un error budget ou burn rate (peut être que je ferai un article sur ce sujet plus tard).
Néanmoins, tout cela pourrait théoriquement être dérivé depuis les traces. Si vous gardez 100 % de vos traces, il est possible de recalculer tout ce que vous voulez depuis ces traces.
L’outillage pour réaliser cela “at scale” est un peu limité pour le moment. Je montrerai dans un prochain article comment réaliser cela en utilisant Mirabelle, un outil que j’ai conçu et sur lequel je viens de rajouter le support d’Opentelemetry traces.
Cela n’est pas forcément une idée nouvelle. A l’époque de protocoles comme statsd les métriques étaient dérivées d’événéments. L’industrie a ensuite changé son fusil d’épaule avec des outils comme Prometheus (et du pull pour récupérer les métriques) mais je pense que l’on va revenir dans les prochaines années à des systèmes orientés “push”, basés sur Opentelemetry, et j’espère les traces.
Je rêve d’un monde où j’ai juste à générer des traces pour remplacer la majorité de mes métriques et de mes logs.
Conclusion
Je pense que le tracing est le futur de l’observabilité. Je n’ai rien d’autre à dire pour conclure cet article ;)