Caching
“There are only two hard things in Computer Science: cache invalidation and naming things.” - Phil Karlton

A cache’s primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer. Trading off capacity for speed, a cache typically stores a subset of data transiently, in contrast to databases whose data is usually complete and durable.
Caches take advantage of the locality of reference principle “recently requested data is likely to be requested again”.
Caching and Memory
Similar to a computer’s memory, a cache is a compact, fast-performing memory that stores data in a hierarchy of levels, starting at level one, and progressing from there sequentially. They are labeled as L1, L2, L3, and so on. A cache also gets written if requested, such as when there has been an update and new content needs to be saved to the cache, replacing the older content that was saved.
No matter whether the cache is read or written, it’s done one block at a time. Each block also has a tag that includes the location where the data was stored in the cache. When data is requested from the cache, a search occurs through the tags to find the specific content that’s needed in level one (L1) of the memory. If the correct data isn’t found, more searches are conducted in L2.
If the data isn’t found there, searches are continued in L3, then L4, and so on until it has been found, then, it’s read and loaded. If the data isn’t found in the cache at all, then it’s written into it for quick retrieval the next time.
Cache hit and Cache miss
Cache hit
A cache hit describes the situation where content is successfully served from the cache. The tags are searched in the memory rapidly, and when the data is found and read, it’s considered a cache hit.
Cold, Warm, and Hot Caches
A cache hit can also be described as cold, warm, or hot. In each of these, the speed at which the data is read is described.
A hot cache is an instance where data was read from the memory at the fastest possible rate. This happens when the data is retrieved from L1.
A cold cache is the slowest possible rate for data to be read, though, it’s still successful so it’s still considered a cache hit. The data is just found lower in the memory hierarchy such as in L3, or lower.
A warm cache is used to describe data that’s found in L2 or L3. It’s not as fast as a hot cache, but it’s still faster than a cold cache. Generally, calling a cache warm is used to express that it’s slower and closer to a cold cache than a hot one.
Cache miss
A cache miss refers to the instance when the memory is searched and the data isn’t found. When this happens, the content is transferred and written into the cache.
Cache Invalidation
Cache invalidation is a process where the computer system declares the cache entries as invalid and removes or replaces them. If the data is modified, it should be invalidated in the cache, if not, this can cause inconsistent application behavior. There are three kinds of caching systems:
Write-through cache

Data is written into the cache and the corresponding database simultaneously.
Pro: Fast retrieval, complete data consistency between cache and storage.
Con: Higher latency for write operations.
Write-around cache

Where write directly goes to the database or permanent storage, bypassing the cache.
Pro: This may reduce latency.
Con: It increases cache misses because the cache system has to read the information from the database in case of a cache miss. As a result, this can lead to higher read latency in the case of applications that write and re-read the information quickly. Read happen from slower back-end storage and experiences higher latency.
Write-back cache

Where the write is only done to the caching layer and the write is confirmed as soon as the write to the cache completes. The cache then asynchronously syncs this write to the database.
Pro: This would lead to reduced latency and high throughput for write-intensive applications.
Con: There is a risk of data loss in case the caching layer crashes. We can improve this by having more than one replica acknowledging the write in the cache.
Eviction policies
Following are some of the most common cache eviction policies:
- First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
- Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
- Least Recently Used (LRU): Discards the least recently used items first.
- Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
- Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
- Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
Distributed Cache
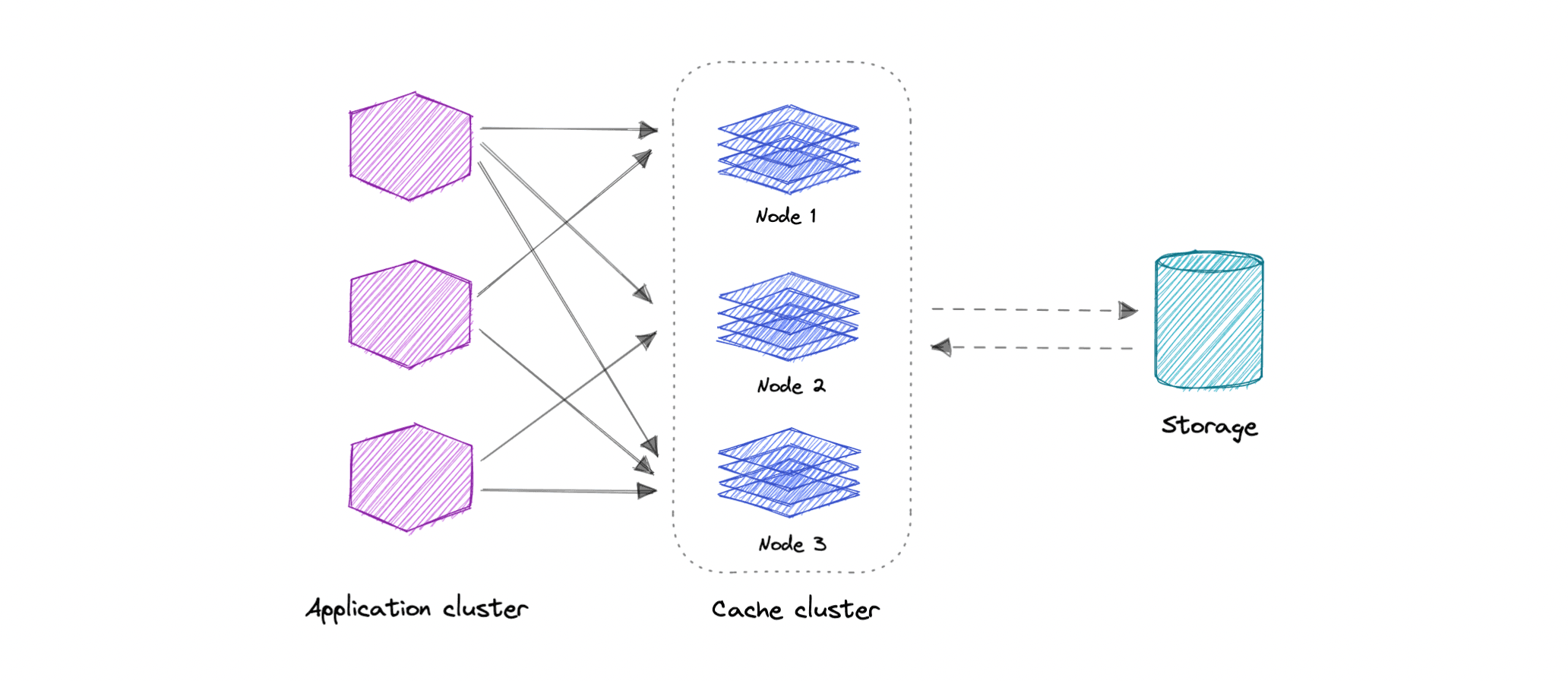
A distributed cache is a system that pools together the random-access memory (RAM) of multiple networked computers into a single in-memory data store used as a data cache to provide fast access to data. While most caches are traditionally in one physical server or hardware component, a distributed cache can grow beyond the memory limits of a single computer by linking together multiple computers.
Global Cache
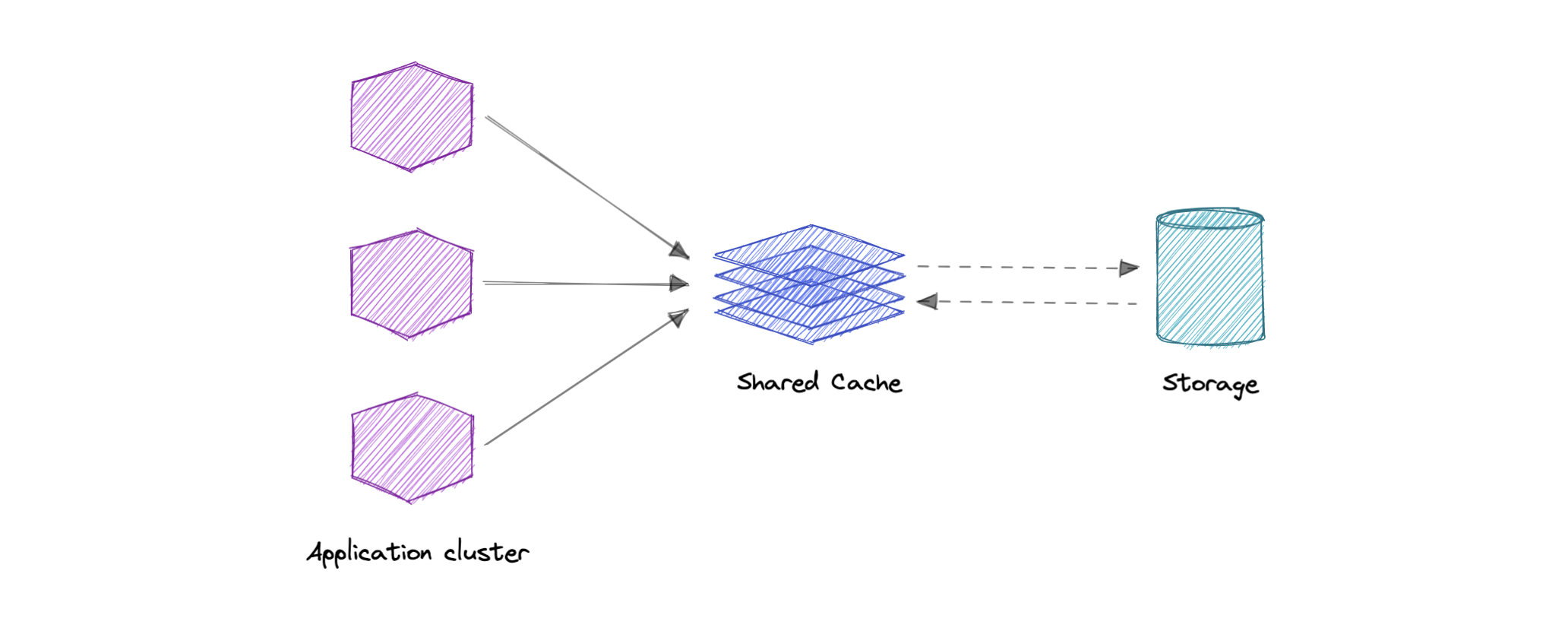
As the name suggests, we will have a single shared cache that all the application nodes will use. When the requested data is not found in the global cache, it’s the responsibility of the cache to find out the missing piece of data from the underlying data store.
Use cases
Caching can have many real-world use cases such as:
- Database Caching
- Content Delivery Network (CDN)
- Domain Name System (DNS) Caching
- API Caching
When not to use caching?
Let’s also look at some scenarios where we should not use cache:
- Caching isn’t helpful when it takes just as long to access the cache as it does to access the primary data store.
- Caching doesn’t work as well when requests have low repetition (higher randomness), because caching performance comes from repeated memory access patterns.
- Caching isn’t helpful when the data changes frequently, as the cached version gets out of sync, and the primary data store must be accessed every time.
It’s important to note that a cache should not be used as permanent data storage. They are almost always implemented in volatile memory because it is faster, and thus should be considered transient.
Advantages
Below are some advantages of caching:
- Improves performance
- Reduce latency
- Reduce load on the database
- Reduce network cost
- Increase Read Throughput
Examples
Here are some commonly used technologies for caching:
src: Caching — PlanetScale - 2025-07-08
Every time you use a computer, caches work to ensure your experience is fast. Everything a computer does from executing an instruction on the CPU, to requesting your X.com feed, to loading this very webpage, relies heavily on caching.
You are about to enjoy a guided, interactive tour of caching: the most elegant, powerful, and pervasive innovation in computing.
Foundation
Everything we do with our computers requires data. When you log into your email, all your messages and contacts are stored as data on a server. When you browse the photo library on your iPhone, they are stored as data on your phone’s storage and/or iCloud. When you loaded this article, it had to fetch the data from a web server.
When designing systems to store and retrieve data, we are faced with trade-offs between capacity, speed, cost, and durability.
Hard-Disk Drives are cheaper per-gigabyte than Solid-State Drives, but the latter are lower latency. Random-Access Memory is faster than both of the above, but is more expensive and volatile.
For a given budget, you can either get a large amount of slower data storage, or a small amount of faster storage. Engineers get around this by combining the two: Pair a large amount of cheaper slow storage with a small amount of expensive fast storage. Data that is accessed more frequently can go in the fast storage, and the other data that we use less often goes in the slow storage.
This is the core principle of caching.
We can see this visualized below. Each colored square represents a unique datum we need to store and retrieve. You can click on the “data requester” to send additional requests for data or click on any of the colored squares in the “slow + large” section to initiate a request that color.
Every time we request a piece of data, the request is first sent to the cache. If it’s there, we consider it a cache hit and quickly send the data back.
If we don’t find it, we call it a cache miss. At this point we pass the request on to the slow storage, find the data, send it back to the cache, and then send it to the requester.
Hit rate
The “hit rate” is the percentage of time we get cache hits. In other words:
hit_rate = (cache_hits / total_requests) x 100
We want to keep the hit rate as high as possible. Doing so means we are minimizing the number requests to the slower storage.
In the setup below we have a small cache, many items to store, and our requests for the items are coming in with no predictable pattern. This leads to a low hit rate.
You can see the hit rate for the above cache and how it changes over time in the bar chart below.
What if instead we have a cache that is nearly the size of our data, with the same random requests pattern?
In this case, we are able to achieve a much higher hit rate.
Increasing the size of our cache increases cost and complexity in our data storage system. It’s all about trade-offs.
Your computer
Perhaps the most widespread form of caching in computers is Random-Access Memory (RAM).
The CPU of a computer is what does all of the “work.” Some call the CPU the brain of a computer. A brain needs memory to work off of, otherwise it isn’t much use.
Any information computers want to store permanently get stored on the hard drive. Hard drives are great because they can remember things even when the computer gets shut off or runs out of battery. The problem is, hard drives are slow.
Click on “CPU” in the visual below to send a request for data to storage. You can also click on any of the colored squares on the “Hard Drive” section to request that specific element.
To get around this, we use RAM as an intermediate storage location between the CPU and the hard drive. RAM is more expensive and has less storage capacity than the hard drive. But the key is, data can be fetched from and written to RAM an order-of-magnitude faster than the time it takes to interact with the hard drive. Because of this, computers will store a subset of the data from the hard drive, the stuff that needs to be accessed more frequently, in RAM. Many requests for data will go to RAM and can be executed fast. Occasionally, when the CPU needs something not already in RAM, it makes a request to the hard drive.
There are actually more layers of caching on a computer than just RAM and disk. Modern CPUs have one or more cache layers for RAM. Though RAM is fast, a cache built directly into the CPU is even faster, so frequently used values and variables can be stored there while a program is running to improve performance.
Most modern CPUs have multiple of these cache layers, referred to as L1, L2, and L3 cache. L1 is faster than L2 which is faster than L3, but L1 has less capacity than L2, which has less capacity than L3.
This is often the tradeoff with caching - Faster data lookup means more cost or more size limitations due to how physically close the data needs to be to the requester. It’s all tradeoffs. Getting great performance out of a computer is a careful balancing act of tuning cache layers to be optimal for the workload.
Temporal Locality
Caching is not only limited to the context of our local computers. It’s used all the time in the cloud to power your favorite applications. Let’s take the everything app: X.com.
The number of tweets in the entire history of X.com is easily in the trillions. However, 𝕏 timelines are almost exclusively filled with posts from the past ~48 hours. After a few days, are rarely viewed unless someone re-posts or scrolls far back into their history. This produces a recency bias.
Let’s consider this banger from Karpathy.
This received over 43,000 likes and 7 million impressions since it was posted over two years ago. Though we don’t have access to the exact trends, a likely trendline for views on this tweet would be:
Tweets, pictures, and videos that were recently posted are requested much more than older ones. Because of this, we want to focus our caching resources on recent posts so they can be accessed faster. Older posts can load more slowly.
This is standard practice for many websites, not just X.com. These websites store much of their content (email, images, documents, videos, etc) in “slow” storage (like Amazon S3 or similar), but cache recent content in faster, in-memory stores (like CloudFront, Redis or Memcached).
Consider the caching visual below. Redder squares represent recent data (“warm” data) whereas bluer squares represent older data that is accessed less frequently (“cold” data). As we click on the app server to send requests, we can see that red data is more frequently accessed. This results in the cache primarily holding onto red data.
After filling up the cache with recent values, click on a few colder values on the database side. These all need to be loaded from the database, rather than being loaded directly from cache.
This is why viewing older posts on someones timeline often take longer to load than recent ones! It does not make much sense to cache values that are rarely needed. Go to someone’s 𝕏 page and start scrolling way back in time. After you get past a few days or weeks of history, this will get noticeably slower.
Spatial Locality
Another important consideration is Spatial Locality.
In some data storage systems, when one chunk of data is read, it’s probable that the data that comes immediately “before” or “after” it will also be read. Consider a photo album app. When a user clicks on one photo from their cloud photo storage, it’s likely that the next photo they will view is the photo taken immediately after it chronologically.
In these situations, the data storage and caching systems leverage this user behavior. When one photo is loaded, we can predict which ones we think they will want to see next, and prefetch those into the cache as well. In this case, we would also load the next and previous few photos.
This is called Spatial Locality, and it’s a powerful optimization technique.
In the example below, you can see how spatial locality works. Each database cell is numbered in sequence. When you click on a cell, it will load the cell and it’s two neighbors into cache.
This prefetching of related data improves performance when there are predictable data access patterns, which is true of many applications beyond photo albums.
Geospatial
Physical distance on a planet-scale is another interesting consideration for caching. Like it or not, we live on a big spinning rock 25,000 miles in circumference, and we are limited by “physics” for how fast data can move from point A to B.
In some cases, we place our data in a single server and deal with the consequences. For example, we may place all of our data in the eastern United States. Computers requesting data on the east coast will have lower latency than those on the west coast. East-coasters will experience 10-20ms of latency, while west-coaster will experience 50-100ms. Those requesting data on the other side of the world will experience 250+ milliseconds of latency.
Engineers frequently use Content Delivery Networks (CDNs) to help. With CDNs we still have a single source-of-truth for the data, but we add data caches in multiple locations around the world. Data requests are sent to the geographically-nearest cache. If the cache does not have the needed data, only then does it request it from the core source of truth.
We have a simple visualization of this below. Use the arrows to move the requester around the map, and see how it affects where data requests are sent to.
We also might choose to have the full data stored in all of the CDN / cache nodes. In this case, if the data never changes, we can avoid cache misses entirely! The only time we would need to get them is when the original data is modified.
Replacement policies
When a cache becomes full and a new item needs to be stored, a replacement policy determines which item to evict to make room for a new one.
There are several algorithms we can use to decide which values to evict and when. Making the right choice here has a significant impact on performance.
FIFO
First In, First Out, or FIFO, is the simplest cache replacement policy. It works like a queue. New items are added to the beginning (on the left). When the cache queue is full, the least-recently added item gets evicted (right).
In this visualization, data requests enter from the top. When an item is requested and it’s a cache hits, it immediately slides up indicating a response. When there’s a cache miss, the new data is added from the left.
While simple to implement, FIFO isn’t optimal for most caching scenarios because it doesn’t consider usage patterns. We have smarter techniques to deal with this.
LRU
Least Recently Used (LRU) is a popular choice, and the industry standard for many caching systems. Unlike FIFO, LRU always evicts the item that has least-recently been requested, a sensible choice to maximize cache hits. This aligns well with temporal locality in real-world data access patterns.
When a cache hit occurs, that item’s position is updated to the beginning of the queue. This policy works well in many real-world scenarios where items accessed recently are likely to be accessed again soon.
Time-Aware LRU
We can augment the LRU algorithm in a number of ways to be time-sensitive. How precisely we do this depends on our use case, but it often involves using LRU plus giving each element in the cache a timer. When time is up, we evict the element!
We might imagine this being useful in cases like:
- For a social network, automatically evicting posts from the cache after 48 hours.
- For a weather app, automatically evicting previous-days weather info from the cache when the clock turns to a new day.
- In an email app, removing the email from the cache after a week, as it’s unlikely to be read again after that.
We can leverage our user’s viewing patterns to put automatic expirations on the elements. We visualize this below. This cache uses LRU, but each element also has an eviction timer, after which it will be removed regardless of usage pattern.
Others
There are other cool/niche algorithms used in some scenarios. One cool one is Least-Frequently Recently Used. This involves managing two queues, one for high-priority items and one for low priority items. The high-priority queue uses an LRU algorithm, and when an element needs to be evicted it gets moved to the low priority queue, which then uses a more aggressive algorithm for replacement.
You can also set up caches to do bespoke things with timings, more complex than the simple time-aware LRU.
Postgres and MySQL
Caches are frequently put in front of a database as a mechanism to cache the results of slow queries. However, DBMSs like Postgres and MySQL also use caching within their implementations.
Postgres implements a two-layer caching strategy. First, it uses shared_buffers, an internal cache for data pages that store table information. This keeps frequently read row data in memory while less-frequently accessed data stays on disk. Second, Postgres relies heavily on the operating system’s filesystem page cache, which caches disk pages at the kernel level. This creates a double-buffering system where data can exist in both Postgres’s shared_buffers and the OS page cache. Many deployments set shared_buffers to around 25% of available RAM and let the filesystem cache handle much of the remaining caching work. The shared_buffers value can be configured in the postgres config file.
MySQL does a similar thing with the buffer pool. Like Postgres, this is an internal cache to keep recently used data in RAM.
Arguably, these are more complex than a “regular” cache as they also have to be able to operate with full ACID semantics and database transactions. Both databases have to take careful measures to ensure these pages contain accurate information and metadata as the data evolves.
Conclusion
I’m dead serious when I say this article barely scratches the surface of caching. We completely avoided the subject of handling writes and updates in caching systems. We discussed very little of specific technologies used for caching like Redis, Memcached, and others. We didn’t address consistency issues, sharded caches, and a lot of other fun details.
My hope is that this gives you a good overview and appreciation for caching, and how pervasive it is in all layers of computing. Nearly every bit of digital tech you use relies on a cache, and now you know just a little more about it.
If you enjoyed this article, you might enjoy these case studies on how large tech companies implement caching: