ACID and BASE consistency models
ACID
The term ACID stands for Atomicity, Consistency, Isolation, and Durability. ACID properties are used for maintaining data integrity during transaction processing.
In order to maintain consistency before and after a transaction relational databases follow ACID properties. Let us understand these terms:
Atomic
All operations in a transaction succeed or every operation is rolled back.
Consistent
On the completion of a transaction, the database is structurally sound.
Isolated
Transactions do not contend with one another. Contentious access to data is moderated by the database so that transactions appear to run sequentially.
Durable
Once the transaction has been completed and the writes and updates have been written to the disk, it will remain in the system even if a system failure occurs.
ACID vs BASE Trade-offs
There’s no right answer to whether our application needs an ACID or a BASE consistency model. Both the models have been designed to satisfy different requirements. While choosing a database we need to keep the properties of both the models and the requirements of our application in mind.
Given BASE’s loose consistency, developers need to be more knowledgeable and rigorous about consistent data if they choose a BASE store for their application. It’s essential to be familiar with the BASE behavior of the chosen database and work within those constraints.
On the other hand, planning around BASE limitations can sometimes be a major disadvantage when compared to the simplicity of ACID transactions. A fully ACID database is the perfect fit for use cases where data reliability and consistency are essential.
I promised this won’t be your typical simple ACID explanation.. i’ve gone through a lot of these and they are more of the same.
here i try to give an overview with deep-dives (especially for Isolation and Durability) and real-world examples.

you will learn beyond the one-liner explanations of ACID, so follow along 👇
Quick intro
ACID transactions (Atomicity, Consistency, Isolation, Durability) keep money, inventory, and messages from slipping through the cracks even when nodes crash, disks fry, or a developer fat-fingers a deploy (me 🤣)

Below is the promised, from my LinkedIn post, long-form dive - with concrete incidents, mini-code snippets, and tips drawn from Designing Data-Intensive Applications (DDIA Ch. 7) 🔥
actually, before all of that, you need to understand what is a database transaction? 👇
A transaction is a sequence of one or more database operations (reads, writes, updates) that the system treats as a single, indivisible unit of work: it either commits in full or rolls back entirely, so partial results never become permanent - even if the client crashes, the network fails, or other sessions run concurrently. During the transaction, intermediate changes remain invisible to other transactions; only after a successful
COMMITdo they become visible, while an error triggersROLLBACK, erasing every step.

great! with this context, you’re ready to learn more about A C I D now 🔥
Atomicity - the “all-or-nothing”
what it is?
A transaction’s steps commit as a single unit; if one step fails, every earlier step is rolled back.
real incident prevented
Wells Fargo 2023: a batch glitch temporarily hid direct-deposit rows for thousands of customers**. A proper atomic batch restore ensured balances snapped back without manual fixes.**
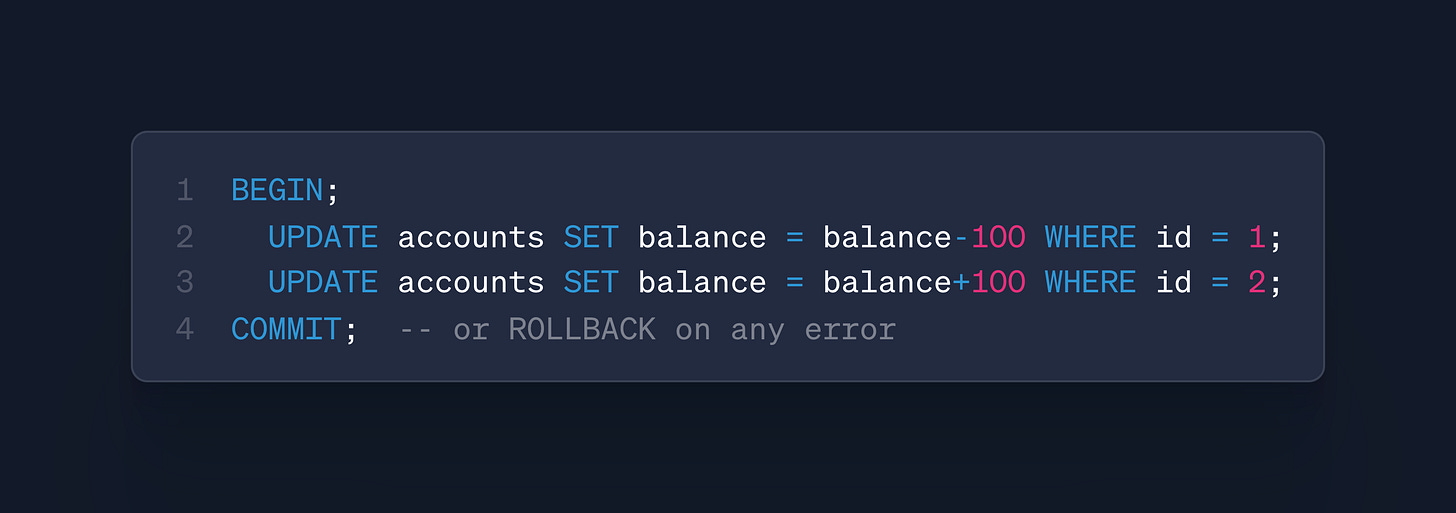
i.e. no penny moves unless both rows update.
ship-it checklist
Use WAL or redo-log before touching data pages.
Catch errors at your API boundary and propagate an explicit rollback (most ORMs do this, but double-check it!)
Consistency – “rules always hold”
what it is?
Every commit must leave the database in a state that satisfies all declared constraints, triggers, and cascades.
real incident prevented
Amazon peak inventory: internal docs note that every “decrement stock” call runs inside a multi-row transaction so this always holds: quantity ≥ 0 , even under Black-Friday fire-hose traffic.

i.e. declarative constraint stops the insert if stock would dip negative.
ship-it checklist
Encode business invariants as constraints, not comments.
Build a chaos test that hammers stock from multiple threads; expect zero negatives.
now, we will dive a bit deeper in the following two as they have a lot of moving parts, which are really nice to have in your SWE toolbox 🧰
Isolation – “no dirty peeks”
tl;dr & what it is?
it’s about what concurrency anomalies you’re willing to tolerate. The SQL standard defines four isolation levels, but real engines implement them with MVCC snapshots, gap locks, or SSI, each with its own corner cases.
real incident prevented
Airbnb prevents accidental double-booking by wrapping each listing row in SELECT … FOR UPDATE, blocking a second checkout until the first finishes.
the standard 4 isolation levels 👇
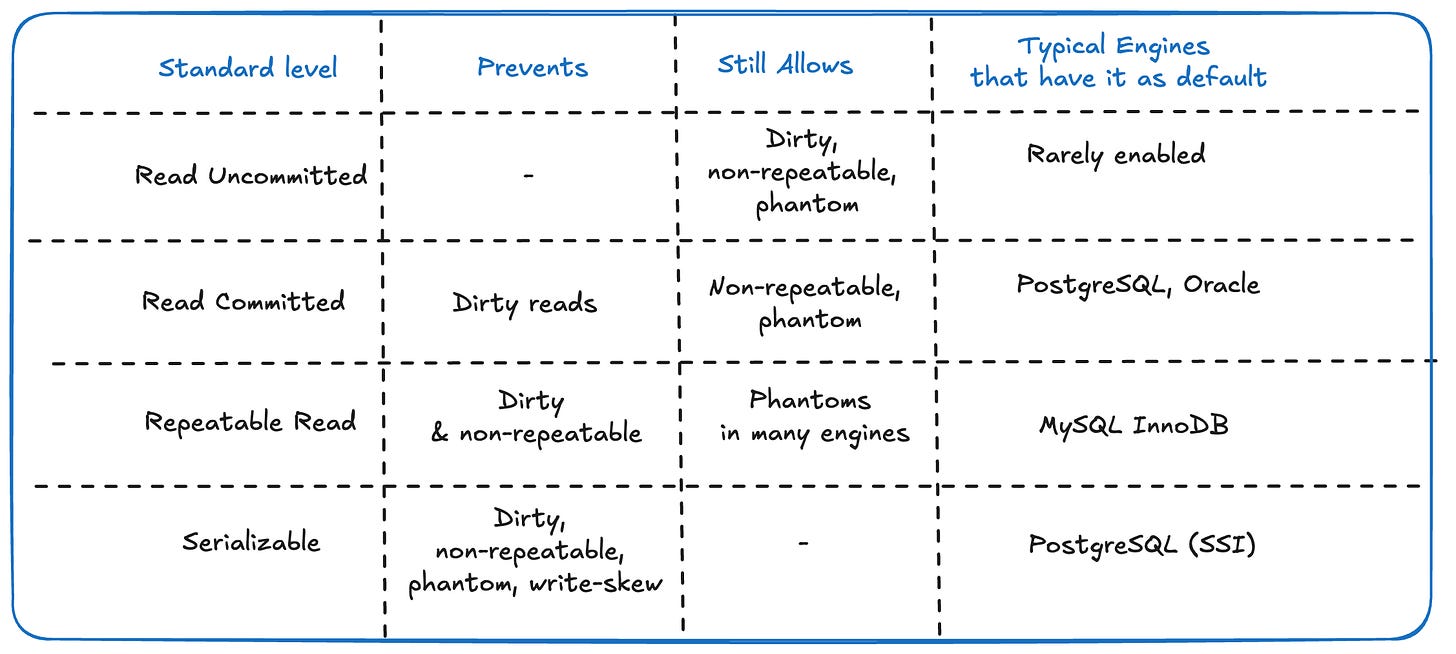
to get even more in-depth refer to this PostgreSQL doc, talking about Transactional Isolation in databases!
engine-specific quirks
as per the table, you can see that each DB engine uses a different isolation level. This isn’t the only difference tho 😵💫
- PostgreSQL uses Serializable Snapshot Isolation (SSI). It runs like Repeatable Read but aborts “dangerous” commit graphs to preserve serialisability.
i.e. Expect smth like:
ERROR: could not serialize access due to read/write dependencies - MySQL InnoDB labels its default Repeatable Read as “phantom-free” - but only when gap locks are taken (e.g.,
SELECT … FOR UPDATE). Plain selects still see phantoms - SQL Server adds Snapshot (MVCC without write-skew protection) and Read Committed Snapshot. Locking vs MVCC chosen with
ALTER DATABASE ….
but how do we pick the right level for our use-case?
firstly, you’ll need to define your workload. then based on it, and with the knowledge you’ve gained here - you can pick the right isolation!
here’s a table that might help! 👇

Pro tip: If you can’t afford full serial but must block lost updates, add a
versioncolumn and retry on conflict - works in every engine.
4. Durability – “pull the plug, data’s still there”
tl;dr & what it is?
it’s about how far you’ll go to ensure a committed write never disappears. Durability lives in the write-ahead log, fsync, and cross-AZ replication—and can still be jeopardised by silent disk or filesystem lies.
real incident prevented
Snap Inc. uses MongoDB with journaling; after a datacenter power loss, chat history replayed from the journal with no manual intervention
imagine this flow (a basic flow for most DBs)

now, what if I told you that each arrow can hide a failure in the system?
.. let’s go through them 💪
Write-Ahead Log (WAL)
- What happens? The engine appends a sequential record of the change, then returns to the client. Actual data pages may be written later
- Why it’s safe? A single 8 KB log flush is cheaper and easier to sync than scattering many pages. PostgreSQL, MySQL /InnoDB, and MongoDB all follow this pattern
fsync() - i.e. “tell the hardware to really put it on disk”
- What happens?
fsync()forces the OS and disk controller to flush their write caches.
replication — “D for double”
- Synchronous mode → Postgres can wait until at least one standby says “WAL safely flushed” (
synchronous_commit = on). That adds ~2–3 ms latency but lets you lose the primary without losing a byte - The AWS Aurora’s twist → AWS Aurora writes every 4 KB block six times across three Availability Zones (AZs) and needs any four copies to acknowledge before committing, giving single-AZ failure tolerance at microsecond scale.
backups — “the last parachute (and the human factor)”
- Why replicas aren’t enough? Software bugs or an
UPDATE … WHERE 1=1replicate instantly; only an independent backup lets you rewind. - The Golden rule? → Automate backups and schedule monthly test restores; an un-tested backup is a résumé generator.
quick checklist on durability:
- WAL enabled and on reliable SSD/NVMe with power-loss protection.
fsync()barriers active → verify with a chaos test- at least one synchronous replica (or Aurora-style quorum) for RPO = 0 workloads
- automated, off-site backups + monthly restore rehearsal
6. ACID in modern system design
- Relational cores inside microservices – use ACID per service boundary; publish / subscribe events after commit. DDIA calls this “transactional outbox”. (Murat Buffalo)
- Multi-row vs. multi-service – keep transactions local; cross-service sagas for everything else.
- Cloud serverless DBs – Spanner, Aurora, and Cosmos DB expose Serializable by default, saving you many foot-guns. (Starburst)
- Interview framing – HelloInterview warns candidates to contrast ACID with BASE for distributed NoSQL stores. (Hello Interview)
Practical Production Cheat-Sheet
- Enable WAL / journaling in every primary DB
- Aim for Read Committed baseline; escalate to Serializable for money-moves or seat-counts
- Use idempotency keys on all external retries to reinforce atomicity
- Add a failure test: yank power or kill -9 and verify automated recovery
- Monitor backups + replica lag so you don’t discover broken durability the hard way
Bottom line: ACID isn’t just an academic acronym - it’s the invisible seat-belt letting billions of dollars, parcels, and bookings move safely every day.
Turn it on, tune it, and test it, and your users will never wonder where their money vanished.