ruby methods are colorless
src: Ruby methods are colorless - 2024-07-15

👋🏼 This is part of series on concurrency, parallelism and asynchronous programming in Ruby. It’s a deep dive, so it’s divided into 10 main parts:
- Your Ruby programs are always multi-threaded: Part 1
- Your Ruby programs are always multi-threaded: Part 2
- Ruby methods are colorless
- Concurrent, colorless Ruby: Part 1, Threads
- Concurrent, colorless Ruby: Part 2, Fiber and its MaNy friends
- Parallel Ruby: Processes, Ractors and alternative runtimes
- Streaming Ruby: Scaling concurrency
- Abstracted, concurrent Ruby
- Closing thoughts, kicking the tires and tangents
- How I dive into CRuby concurrency
You’re reading “Ruby methods are colorless”. I’ll update the links as each part is released, and include these links in each post.
📝 A quick note on Ruby runtimes
I’m approaching this series from the perspective of CRuby. This is the original and most popular/common Ruby runtime. I’m also focusing primarily on Ruby 3.2/3.3+. This matters because it informs how things like Threads and Fibers behave.
First, some context
Last year I read a tweet from @ThePrimagen about his experience with Go1. In it he mentioned some strengths and weaknesses (cheekily), and then he mentioned a phrase I’d never heard before: “colorless functions”.
real talk, colorless functions [are] amazing and I think that most people don’t realize how great it really is
– @ThePrimeagen
Function colors
Curious to understand what a “colorless function” is, a quick search returned this article as the first result: What color is your function?2
In it, Bob Nystrom goes through a fictional language (spoiler: it’s Javascript/node.js) that breaks functions down into one of two “colors”:
- Every function has a color
- The way you call a function depends on its color
- You can only call a red function from within a red function
- Red functions are more painful to call
- Some core library functions are red
It’s an allegory… red functions are asynchronous ones
– Nystrom
Red and blue functions equate to asynchronous and synchronous functions. And having to indicate the color of your function infects the rest of your code and the API decisions you make.
The road to hell is paved with callbacks
Nystrom’s article was written in 2015 while Javascript/node was still in its callback hell3 phase. Any operation that could block, like reading a file, making an HTTP call, or querying a database had to be done using a callback. Callbacks proliferated throughout your code - so asynchronous, red functions were plentiful and painful to interact with.
In JavaScript, everything happens in a single-ish threaded context called the “event loop”. You can’t block the loop - so you would set a callback to know when a blocking call completed:
readFile(path, (content, err) => {
if (err) { throw ''; }
saveFile(content, (file, err) => {
// and on and on...
});
});
After callbacks, he alludes to what would be the subsequent Promises phase of Javascript/node.js with his section “I promise the future is better”. An ergonomic improvement to callbacks but still cumbersome, and does not solve most red/blue pain points:
readFile(path)
.then((content) => {
saveFile(content)
.then((file) => {})
.catch(err) => {})
})
.catch((err) => console.error(err));
Finally he describes the async/await phase in “I’m awaiting a solution”, which leads us to modern Javascript:
try {
const content = await readFile(path);
} catch (err) {
console.error(err);
}
try {
const file = await saveFile(content);
} catch (err) {
console.error(err);
}
Invasive async/await
I’ll edit “I’m awaiting a solution” for modern JS, where he notes:
- Synchronous functions return values, async ones return
Promise<T>(Promise containing type T) wrappers around the value.- Sync functions are just called, async ones need an
await.- If you call an async function you’ve got this wrapper object when you actually want the
T. You can’t unwrap it unless you make your function async and await it.”– Nystrom
#3 is the particularly infectious bit. Async code bubbles all the way to the top. If you want to use await, then you have to mark your function as async. Then if someone else calling your function wants to use await, they also have to mark themselves as async, on and on until the root of the call chain. If at any point you don’t then you have to use the async result (in JavaScript’s case a Promise<T>).
async function readFile(): Promise<string> {
return await read();
}
async function iCallReadFile(): Promise<string> {
return await readFile();
}
async function iCallICallReadFile(): Promise<string> {
return await iCallReadFile();
}
function iGiveUp(callback) {
iCallICallReadFile()
.then(callback)
.catch((err) => {})
}
Once your language is broken down into async and synchronous functions, you can’t escape it.
Even more onerous, if it isn’t built into your language core like JavaScript/node.js, adding it later means modifying your entire runtime, libraries and codebases to understand it. This was (still can be?) a painful transition for languages like Python and Rust.
// et tu, Rust?
async fn main() {
let content = read_file().await;
}
What makes Ruby colorless?
So what does a “blue” (synchronous) method look like in Ruby?
And what does that same “red” (asynchronous) call look like?
Wait. Is that right? Surely there must be more nuance?
HTTP?
response = Net::HTTP.get(
URI("https://example.com")
)
Shell calls!
Process spawning??
pid = fork
# good stuff
end
Process::Status.wait pid
Mutex locks?!?
DNS resolution!??!
ip = Resolv.getaddress "ruby-lang.org"
Sleep!?!!!
😮💨😮💨😮💨
Well that’s nice! There is no difference between asynchronous and synchronous methods, so no color. We get asynchronous behavior for free. Blog post over!?
Well… not exactly. We still don’t know how we get that behavior.
In the section “What language isn’t colored?” Nystrom specifically mentions Ruby being one of a few colorless languages4:
…languages that don’t have this problem: [Java,] Go, Lua, and Ruby.
Any guess what they have in common?
Threads. Or, more precisely: multiple independent callstacks that can be switched between. It isn’t strictly necessary for them to be operating system threads. Goroutines in Go, coroutines in Lua, and fibers in Ruby are perfectly adequate.
– Nystrom
So Ruby is colorless, and to be colorless you need independent call stacks that you can switch between. And apparently Threads and Fibers can give you that.
What does that mean and what does that enable? And since Nystrom’s article was written in 2015 - is there anything new to Ruby since then?
A nested concurrency model 🪆
In Your Ruby programs are always multi-threaded: Part 2, we briefly discussed that Ruby has a layered concurrency model and that the best way to describe it is as a nesting doll - as you pull away the outer layers, you find new layers of concurrency inside.
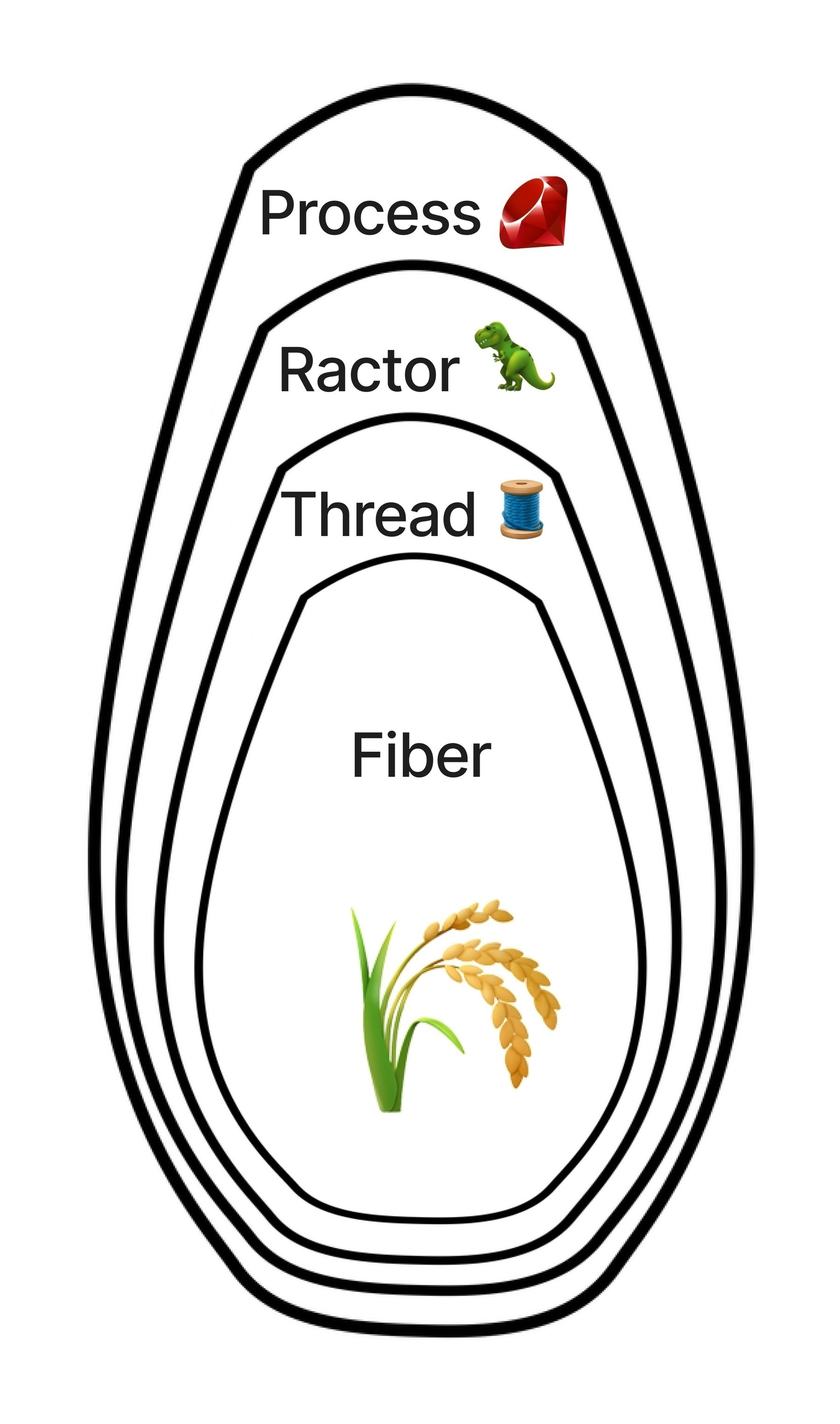
Here’s my key for mapping icons to concurrency
- 💎 represents a Ruby process, which is essentially another instance of Ruby itself
- 🦖 represents a Ruby Ractor. Ractor stands for Ruby Actor, as in the Actor model. But I always think of the word “Raptor” instead, so I represent it with a Dinosaur 🤷🏻♂️
- 🧵 represents a Ruby Thread. It’s a thread icon, for obvious reasons
- 🌾 represents a Ruby Fiber. I think of wheat when I think of Fibers, hence 🌾
As a refresher, in your own Ruby code, you can easily inspect each layer directly:
puts "Process #{Process.pid}"
puts " Ractor #{Ractor.current}"
puts " Thread #{Thread.current}"
puts " Fiber #{Fiber.current}"
# Process 123
# Ractor #<Ractor:#1 running>
# Thread #<Thread:0x0... run>
# Fiber #<Fiber:0x0... (resumed)>
Your code is always operating within a specific instance of each layer. Mostly you can access those instances with a call to current.
Each layer has unique characteristics when it comes to running concurrent code. Some can operate in parallel, executing independent Ruby code at the exact same time. Others run your Ruby code concurrently, moving back and forth between them but never running simultaneously.
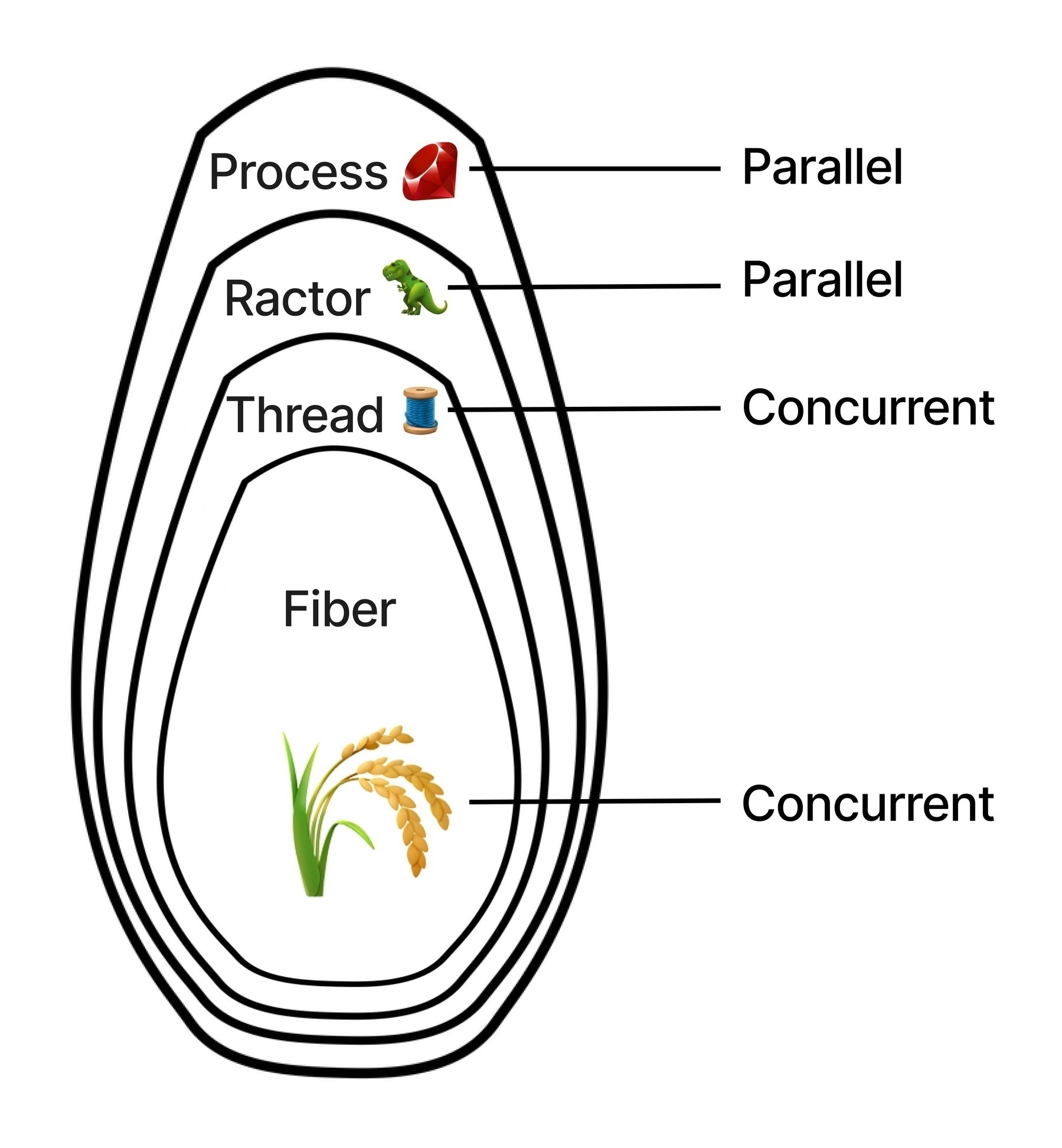
source: jpcamara.com
The outermost layer is a Process 💎. Every program on every common operating system (Linux, Windows, macOS) runs inside a process - it’s the top-level unit of execution in the OS. You can have as many processes as your OS will allow - but the number of CPU cores determine how many processes can run in parallel. Multiple Ruby processes can run in parallel but they live in isolated memory spaces - they have no simple way of communicating with each other.
pid = fork do
#...
end
Process::Status.wait pid
Internally, a Ruby process is made up of Ractors 🦖. Ractors don’t have a direct parallel in the OS - they’re a unique Ruby structure which wrap native OS threads5. Multiple Ractors can run Ruby code in parallel, and they have strict sharing rules to keep them memory safe - so you can only communicate between them by passing messages. Those messages can copy data, or they can move objects completely between Ractors and change ownership. Ractors sound pretty nice, but are still experimental. Regardless, every Ruby process starts out with a single Ractor that your Ruby code runs inside of.
ractor = Ractor.new do
#...
end
ractor.take
Inside of Ractors, you have Threads 🧵. Threads are created 1:1 with threads on your operating system6. These threads share the same memory space with each other, and every thread created within a process shares the same memory space as the process, and spends its lifetime there. Because threads share the same memory space they have to be carefully coordinated to safely manage state. Ruby threads cannot run CPU-bound Ruby code in parallel, but they can parallelize for blocking operations. Threads run preemptively, which means they can swap out of your code at any time, and move to other Ruby code. Every Ruby Ractor starts out with a single thread that your Ruby code runs inside of.
thread = Thread.new do
#...
end
thread.join
Inside of threads, you have Fibers 🌾. Fibers are another structure with no direct OS equivalent (though they have parallels in other languages). Fibers are a tool intended for lightweight, cooperative concurrency. Like Ruby threads, Fibers share a memory space, but their coordination is more deterministic. Also like Ruby threads, Fibers cannot run CPU-bound Ruby code in parallel, but using a FiberScheduler can parallelize for blocking operations. Every Ruby thread starts out with a single fiber that your Ruby code runs inside of.
fiber = Fiber.new do
#...
end
fiber.resume # transfer / Fiber.schedule
When a Ruby program starts, all four layers start with it. The Process 💎 starts, it creates a Ractor 🦖, which creates a Thread 🧵, which creates a Fiber 🌾. Ultimately, your Ruby code is in the context of all 4, but most specifically the fiber. Each layer is always active in a Ruby program whether you use them directly or not7. We can utilize each in unique ways as well.
That’s a lot! In subsequent posts you’ll learn why each layer exists and the values each provides. Every layer will get some discussion - but as it relates to asynchronous, colorless programming, threads and fibers are the most relevant.
Colorless threads 🧵 and fibers 🌾
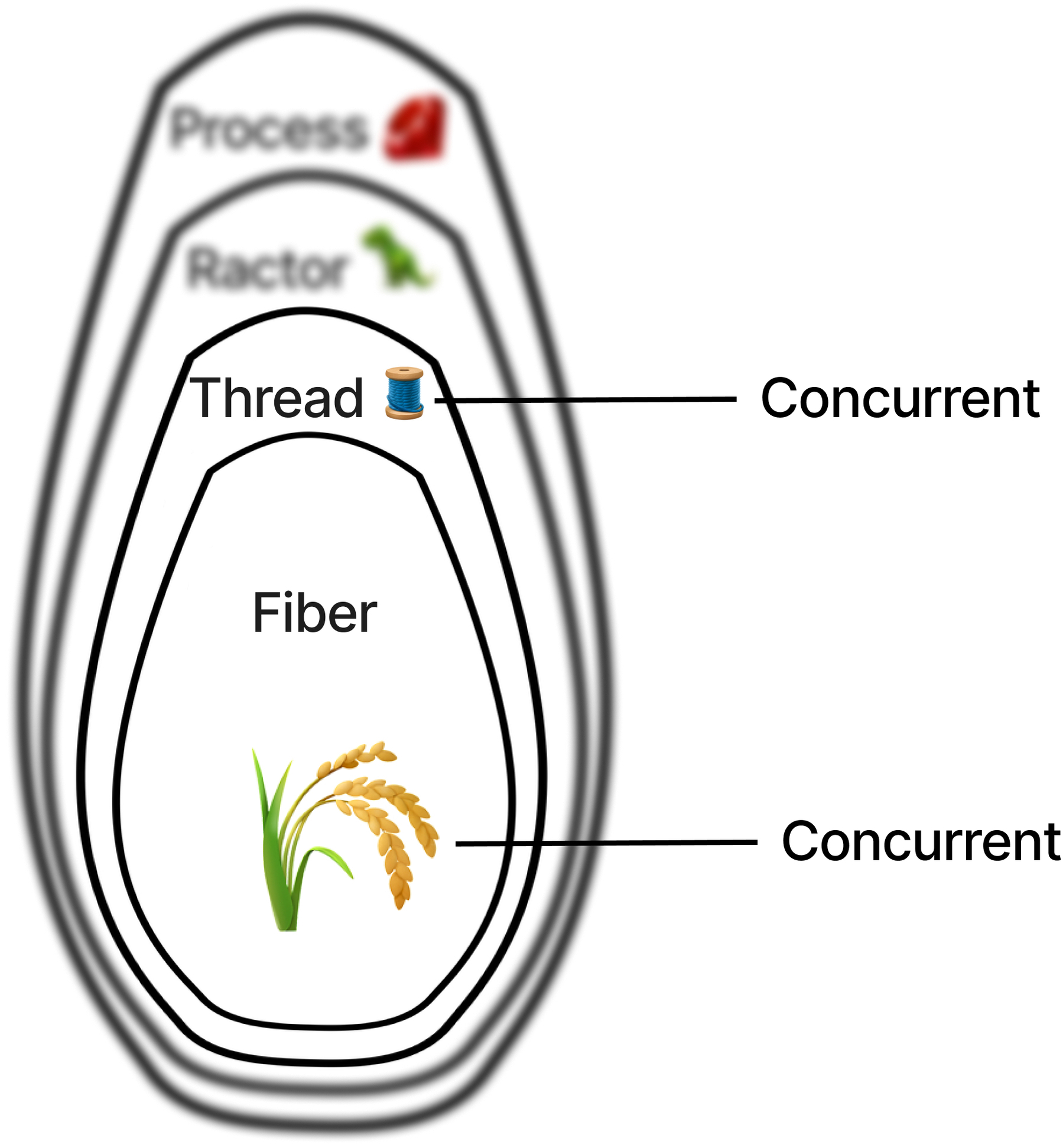
source: jpcamara.com
Threads 🧵 are one of the oldest and most common units of concurrency in Ruby. They’re the OG for splitting up concurrent chunks of work. They’ve been in Ruby since Ruby 1.18 and have enabled colorless calls for many years.
Fibers 🌾 aren’t too young themselves, but are about 10 years younger than their older sibling Threads. They were released in Ruby 1.9, but remained a bit of an esoteric option for a long time. They offered a form of concurrency, but for most use-cases it didn’t really help anyone - unlike Threads, they didn’t enable colorless programming at first.
But ever since Ruby 3, Fibers have been given superpowers in the form of the FiberScheduler. By using a FiberScheduler, Fibers can now provide seamless, colorless programming.
So both threads and fibers offer colorless, concurrent programming. We’ve got a definition for colorless, but what about concurrency?
What does it mean to be concurrent?
The most popular source for a definition of concurrency is from the creator of Go, Rob Pike, in his talk concurrency is not parallelism. Another member of the Go team summarized it:
When people hear the word concurrency they often think of parallelism, a related but quite distinct concept. In programming, concurrency is the composition of independently executing processes, while parallelism is the simultaneous execution of (possibly related) computations. Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
source: https://go.dev/blog/waza-talk
They describe it as a way of composing tasks. It allows you to spread out and coordinate work. How that work is ultimately executed is not relevant to whether the code is concurrent or not.
Look at the activity monitor for your OS right now. If you were to count the number of processes and threads, it would vastly exceed the number of available cores. And yet everything still chugs along smoothly. That’s concurrency in action.
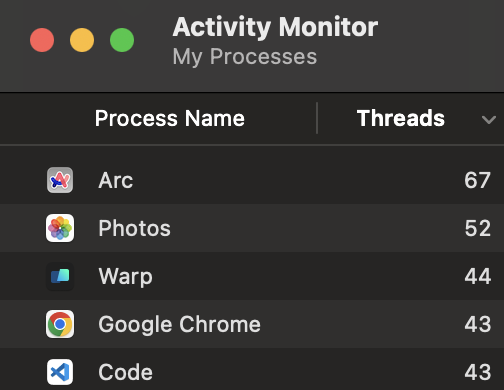
There are over 200 threads associated with just these 5 apps. I don’t have 200 CPU cores, so only a handful of them could ever be active in parallel. But all of them could operate concurrently.
Having said all that - we do want our work to happen as parallel as possible in most cases. We want to maximize our resources and parallelize as much as we can.
In Rob Pike’s concurrency talk, he used the Go mascot, the gopher, to demonstrate how his task (incinerating obsolete language manuals 😅) was composed, and how it could be run in parallel, or with one gopher at a time, but it was still concurrent:
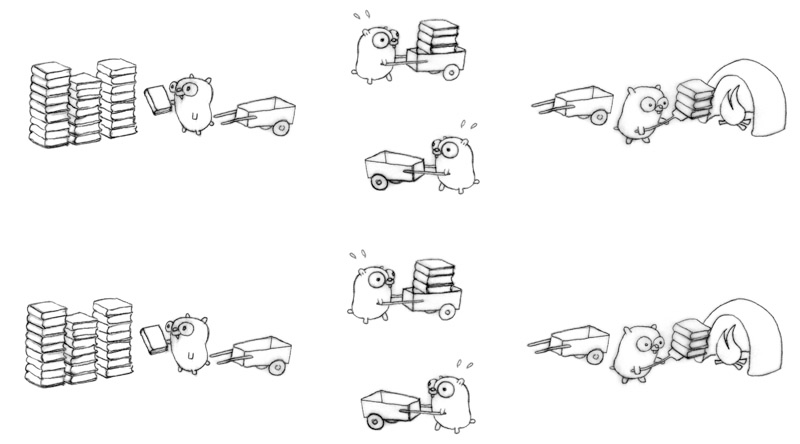
Go’s gophers are kind of fun. Let’s use some concurrency mascots for Ruby to show our own example.
Process!

Ractor!

Thread!

Fiber!

CPU!

source: jpcamara.com
As a baseline, Processes and Ractors can run in parallel for as many cores as are available:
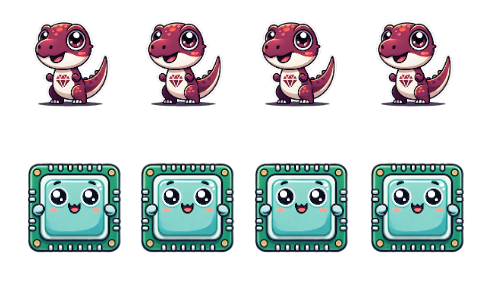

But Threads and Fibers, while concurrent, effectively only parallelize against one core at a time9:
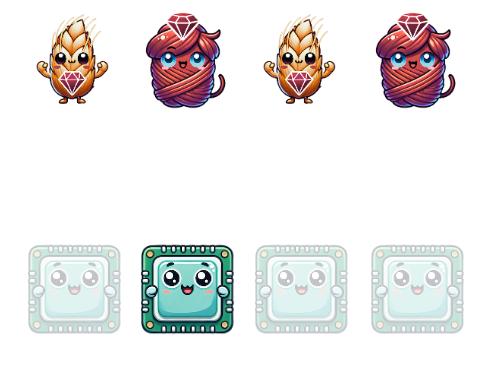
What happens when we start scaling Processes and Ractors past the number of available cores?
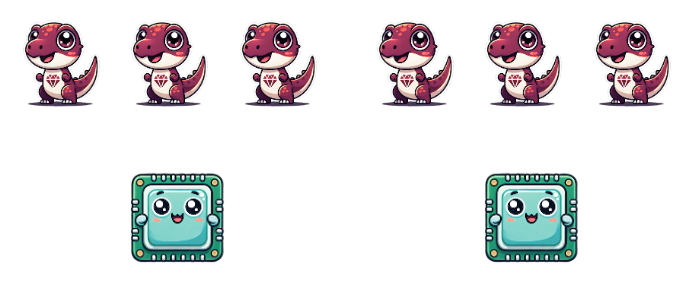
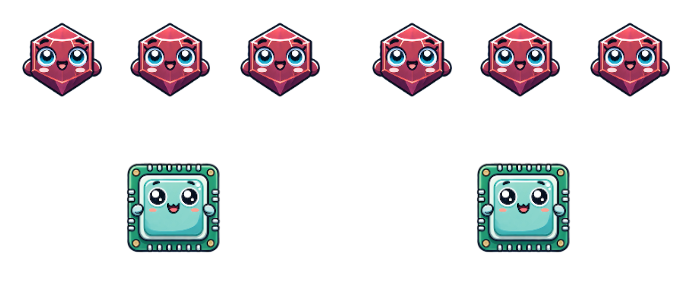
Once we exceed the ability to parallelize, we are concurrent in the same way as Threads and Fibers! This model allows our units of concurrency adapt to the environment - when cores are available they can run in parallel, and when cores are not available they can swap between each other, transparently to the program itself. Every program eventually becomes concurrent as it scales, at least for CPU-bound processing.
But this leaves Threads and Fibers looking pretty limited. They allow you to breakup your work into independent, interleaving tasks, operating concurrently on Ruby code. But what good is that since they never operate in parallel… or do they?
Colorless calls
How does this all relate to colorless methods?
Let’s see with an example. In our example, we’re just traversing a few different websites we care about, and we want to retrieve them as efficiently as possible.
First we try it with threads. For demonstration purposes, we use the httpbin.com/delay endpoint to simulate delays in responses.
require "net/http"
def log_then_get(url, context)
puts "Requesting #{url}..."
get(url, context)
end
def get(uri, context)
response = Net::HTTP.get(uri)
puts caller(0).join("\n")
response
end
def get_http_thread(url)
Thread.new do
log_then_get(URI(url), Thread.current)
end
end
def get_http_via_threads
threads = []
threads << get_http_thread(
"https://httpbin.org/delay/3?ex=1"
)
threads << get_http_thread(
"https://httpbin.org/delay/3?ex=2"
)
threads << get_http_thread(
"https://httpbin.org/delay/3?ex=3"
)
threads << get_http_thread(
"https://httpbin.org/delay/3?ex=4"
)
threads.map(&:value)
end
now = Time.now
get_http_via_threads
puts "Thread runtime: #{Time.now - now}"
This code is doing a few things:
- It’s split into multiple methods to create a callstack (effectively, a backtrace). This callstack allows us to demonstrate that we maintain the position and state of each method call, even when we switch between threads.
- It creates four threads and appends them to an array. After those threads are initialized they go into a ready state, available to be run by the thread scheduler.
- It calls
valueon each thread. This blocks the program until each thread finishes and returns the last value returned from the thread. Once we block the main thread withvalue, the other threads have an immediate opportunity to start running. In this case we block until each thread finishes making an HTTP call.
# > bundle exec ruby main.rb
#
# Requesting https://httpbin.org/delay/3?ex=1...
# Requesting https://httpbin.org/delay/3?ex=2...
# Requesting https://httpbin.org/delay/3?ex=3...
# Requesting https://httpbin.org/delay/3?ex=4...
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:18:in `block in get_http_thread'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:18:in `block in get_http_thread'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:18:in `block in get_http_thread'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:18:in `block in get_http_thread'
# Thread runtime: 3.340238554
Second we try it with fibers:
require "net/http"
require "async"
# Same #log_then_get
# Same #get
def get_http_fiber(url, responses)
Fiber.schedule do
responses << log_then_get(URI(url), Fiber.current)
end
end
def get_http_via_fibers
Fiber.set_scheduler(Async::Scheduler.new)
responses = []
responses << get_http_fiber(
"https://httpbin.org/delay/3?ex=1", responses
)
responses << get_http_fiber(
"https://httpbin.org/delay/3?ex=2", responses
)
responses << get_http_fiber(
"https://httpbin.org/delay/3?ex=3", responses
)
responses << get_http_fiber(
"https://httpbin.org/delay/3?ex=4", responses
)
responses
ensure
Fiber.set_scheduler(nil)
end
now = Time.now
get_http_via_fibers
puts "Fiber runtime: #{Time.now - now}"
Same as before, this code is doing a few things:
- We are split into multiple methods to create a callstack. Same as with threads, this callstack allows us to demonstrate that we maintain the position and state of each method call, even when we switch between fibers.
- It schedules four Fibers. We append to an array inside the
Fiber.scheduleto get the result. Unlike threads, a scheduled fiber will start running its block immediately. - The fibers will coordinate between themselves and the current fiber. When we unset the FiberScheduler using
set_scheduler(nil)in ourensure, theAsync::Schedulermakes sure all fibers have finished running before returning.
This results in the following, similar backtrace:
# > bundle exec ruby main.rb
#
# Requesting https://httpbin.org/delay/3?ex=1...
# Requesting https://httpbin.org/delay/3?ex=2...
# Requesting https://httpbin.org/delay/3?ex=3...
# Requesting https://httpbin.org/delay/3?ex=4...
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:24:in `block in get_http_fiber'
# .../async-2.6.3/lib/async/task.rb:160:in `block in run'
# .../async-2.6.3/lib/async/task.rb:330:in `block in schedule'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:24:in `block in get_http_fiber'
# .../async-2.6.3/lib/async/task.rb:160:in `block in run'
# .../async-2.6.3/lib/async/task.rb:330:in `block in schedule'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:24:in `block in get_http_fiber'
# .../async-2.6.3/lib/async/task.rb:160:in `block in run'
# .../async-2.6.3/lib/async/task.rb:330:in `block in schedule'
# main.rb:12:in `get'
# main.rb:7:in `log_then_get'
# main.rb:24:in `block in get_http_fiber'
# .../async-2.6.3/lib/async/task.rb:160:in `block in run'
# .../async-2.6.3/lib/async/task.rb:330:in `block in schedule'
# Fiber runtime: 3.291355669
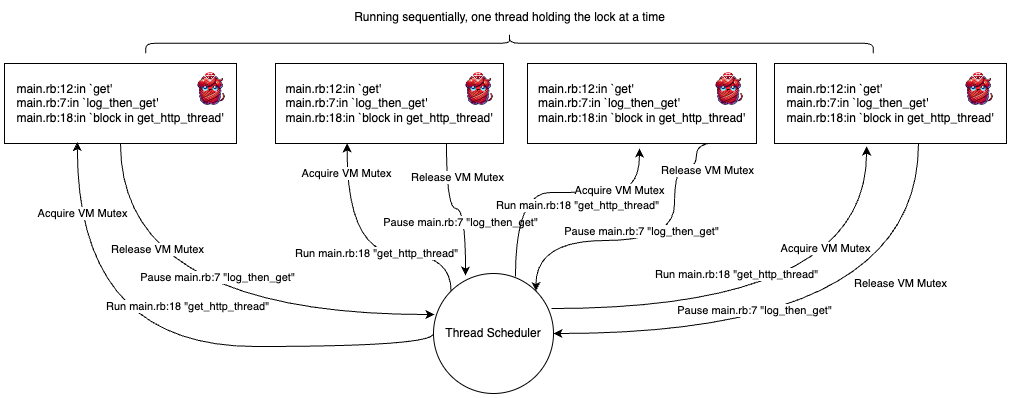
If we visualize what’s happening, we see how things are getting coordinated. It’s nearly identical between the two:
Threads:
Fibers:
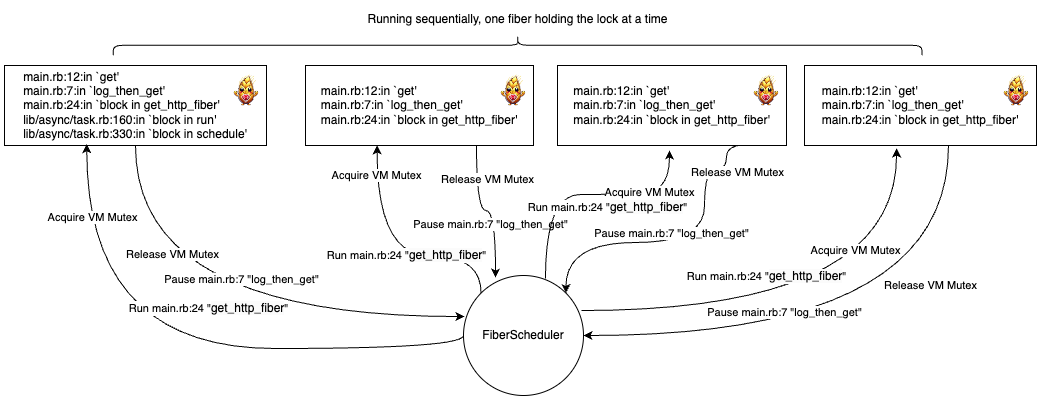
👆🏼This diagram does look pretty sequential - that’s odd huh?
And here is what happens once we are waiting for a response:
Threads:
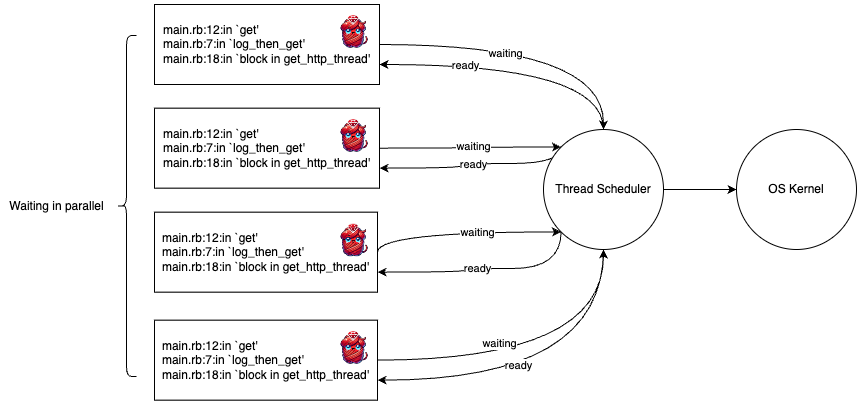
Fibers:
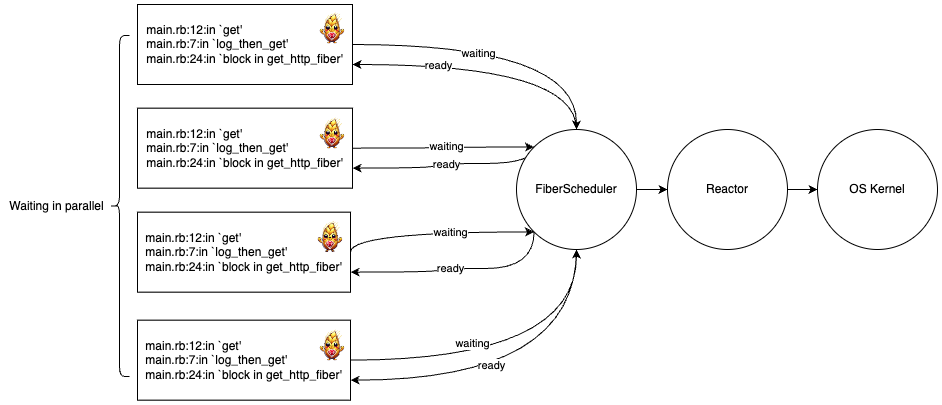
👆🏼Oh, that seems better!
Running these HTTP methods is the same if I run it with no threads/fibers, 4 threads/fibers, or 400 threads/fibers. The code never changes, the execution context is all we need to start operating asynchronously. Something is coordinating for us behind-the-scenes, and we’re able to handle our HTTP calls in parallel 🙌🏼.
This lines up with our timing. In each example we ran 4 HTTP calls, all guaranteed to block for around 3 seconds. Despite that, each example finished in roughly 3 seconds, rather than the 12 seconds it would take if they had run sequentially.
# Fiber runtime: 3.291355669
# Thread runtime: 3.340238554
To paraphrase Bob Nystrom’s article one last time, we can apply his original points about Go almost perfectly to Ruby threads/fibers:
As soon as you do any IO operation, it just parks that thread/fiber and resumes any other one that isn’t blocked on IO.
If you look at the IO operations in the standard library, they seem synchronous. In other words, they just do work and then return a result when they are done. But it’s not that they’re synchronous in the sense that it would mean in JavaScript. Other Ruby code can run while one of these operations is pending. It’s that Ruby has eliminated the distinction between synchronous and asynchronous code.
As we saw in the initial examples of colorless method calls - it’s not purely IO that parks and resumes. It’s the majority of blocking operations. Here’s another example:
# Threads
threads = [
Thread.new { sleep 5 },
Thread.new { `ruby -v` },
Thread.new {
noop = fork {}
Process.wait noop
}
]
results = threads.map(&:value)
# Fibers
Fiber.set_scheduler(Async::Scheduler.new)
fibers = [
Async { sleep 5 },
Async { `ruby -v` },
Async {
noop = fork {}
Process.wait noop
}
]
results = fibers.map(&:wait)
We fork a ruby process, run a command line script to get the current ruby version using ruby -v and sleep - all in parallel.
A quick aside on Async
Manually setting the FiberScheduler and manually unsetting it is just to more clearly demonstrate the interface. But you would normally run the block format:
Async do
fibers << get_http_fiber #...
end
You’d also use the Async helpers instead of Fiber.schedule, which have a more robust available API:
def get_http_fiber(url)
Async do
log_then_get(URI(url), Fiber.current)
end
end
Digging deep
My toy examples aside, this is one of the things that makes threaded/fibered web servers like Puma/Falcon and threaded job servers like Sidekiq/GoodJob so powerful - parallelizing blocking operations. Every time one of your job or web server threads/fibers reads a file, queries a database, makes an HTTP call, or waits for a shared resource, Ruby parks the thread/fiber and another thread/fiber is able to take over. Depending on the type of workload you can have dozens/hundreds/thousands of threads/fibers running concurrently, and blocking in parallel. We’ll push some limits on that later in the series to see where that might break down, and how we can keep scaling past those limits!
Now that we understand what colorless Ruby programming means and how it works - we’re left with some questions.
- Why would we need or want both Threads and Fibers?
- Why do some languages choose to introduce color to their languages? Are there upsides to color?
- What is the deal with those “VM locks”?
- What does the “OS Kernel” have to do with parallel IO?
- What’s a Reactor?
- Is there a best concurrency option?
- Are there abstractions you should be using?
- What’s the point of concurrency without parallelism?
- We also keep talking about parallelizing blocking operations - why don’t threads and fibers already allow you to parallelize everything?
To answer these questions (and more), we’re going to dig pretty far into the ruby runtime to better understand Ruby threads, fibers and other forms of concurrency in Ruby.
Let’s start with the OG, Threads, in “Concurrent, Colorless Ruby: Part 1, Threads”. More soon! 👋🏼
PS: A historical sidenote - Ruby had its own callback phase
It was 2009. The Black Eyed Peas were on top of the charts with “Boom Boom Pow”. Microsoft had just launched Windows 7. Avatar was taking off in the box office. And of course most important of all, node.js was released (😉). During a brief ensuing insanity, everyone thought it would devour the world of web development.
Like any new option, it ultimately took its place alongside other tools, but it had a big influence in the popularity of the reactor pattern.
The reactor pattern is an event loop that registers events with the operating system and efficiently multiplexes them. It was a way of solving the C10K problem - a solution for serving 10 thousand+ clients from a single server.
To get a great insight into the Ruby concurrency landscape at that time, and why the node.js model seemed so appealing, see this post from Yehuda Katz in 2010 - https://yehudakatz.com/2010/08/14/threads-in-ruby-enough-already/. In summary:
- Early Rails was not thread-safe so you could only scale with Processes
- Once Rails was “thread-safe”, it started with a giant mutex around the entire framework that meant only one thread could do anything at a time, including blocking operations
- Even threaded servers at the time would often wrap things poorly and too broadly in mutexes
- The most popular database for Ruby/Rails at the time, MySQL, had a Ruby driver which did not release the thread on blocking operations
- Ruby 1.9 was the first Ruby to map to real operating system threads and loads of people still worked in Ruby 1.8
- He doesn’t mention it specifically, but the gem landscape was also pretty scary in terms of thread safety because many people did not understand or worry about it prior to that point. Things are definitely better now, though I’d recommend reviewing my Your Ruby Programs are always multi-threaded posts, and specifically tips for auditing gems
It was a concurrency mess.
No wonder node.js seemed like a magical concurrency silver bullet. A single process handling hundreds to thousands of users vs dozens of heavyweight processes handling a paltry comparative amount.
In the Ruby world the reactor pattern was served by a tool called EventMachine. We’ll talk a bit deeper about EventMachine in the “Concurrent, Colorless Ruby” fiber post later, but it was solely callback based.
EventMachine.run do
redis = EM::Hiredis.connect
http = EM::HttpRequest.new(
"http://google.com/"
).get query: { "keyname" => "value" }
http.errback { EventMachine.stop }
http.callback {
parse(http.response).each |link| do
req = EM::HttpRequest.new(link).get
req.callback {
body = req.response
redis.set(link, body).callback {
# and on and on
}
}
end
}
EventMachine.stop
end
You can see how messy coding like this becomes, just like the original callback model we presented in JavaScript.
EventMachine was a powerful scaling option, and people still maintain EventMachine-based code today, but it was at odds with the normal flow of Ruby code. Ruby could have moved to red and blue style calls like some other languages to clean that up, but instead superseded those Reactor efforts with the FiberScheduler.
- The programming language, not the game 🙂 ↩︎
- Turns out prime did a reaction video on it as well https://youtu.be/MoKe4zvtNzA ↩︎
- In case this seems like a confusing and bizarre title, it’s a play on “the road to hell is paved with good intention” https://en.wikipedia.org/wiki/The_road_to_hell_is_paved_with_good_intentions 🌈 ↩︎
- I’m sure this is not exhaustive, the list is just illustrative and represents some popular languages. You don’t need to defend your language of choice 😉 ↩︎
- They stand for Ruby Actors so it is a Ruby form of the actor model. It works similarly to JavaScript WebWorkers in that they are isolated and require strict rules for sharing to enforce thread safety ↩︎
- For now, as we’ll discuss later ↩︎
- As with most things, there’s even more nuance to the layering and we’ll touch on it a bit later ↩︎
- But have evolved significantly since then. This also required community support in addition to language support ↩︎
- It’s more nuanced than this, and this is more for illustrative puposes. Even though they don’t run Ruby code in parallel, threads and fibers may still be tied to separate CPUs. ↩︎