microservices antipatterns and pitfalls - Data-Driven Migration AntiPattern
microservice is about creating lots of small, distributed single-purpose services, with each service owning its own data. This service and data coupling supports the notion of a bounded context and a share-nothing architecture, where each service and its corresponding data are compartmentalized and completely independent from all other services, exposing only a well-defined interface (the contract). This bounded context is what allows for quick and easy development, testing, and deployment with minimal dependencies.
The data-driven migration antipattern occurs mostly when you are migrating from a monolithic application to a microservices architecture. The reason this is an antipattern is that it seems like a good idea at the start to migrate both the service functionality and the corresponding data together when creating microservices, but as you will learn in this chapter, this will lead you down a bad path that can result in high risk, excess cost, and additional migration effort.
There are two primary goals during any microservices conversion effort. The first goal is to split the functionality of the monolithic application into small, single-purpose services. The second goal is to then migrate the monolithic data into small databases (or separate schemas) owned by each service. Figure 1-1 shows what a typical migration might look like when both the service code and the corresponding data are migrated at the same time.
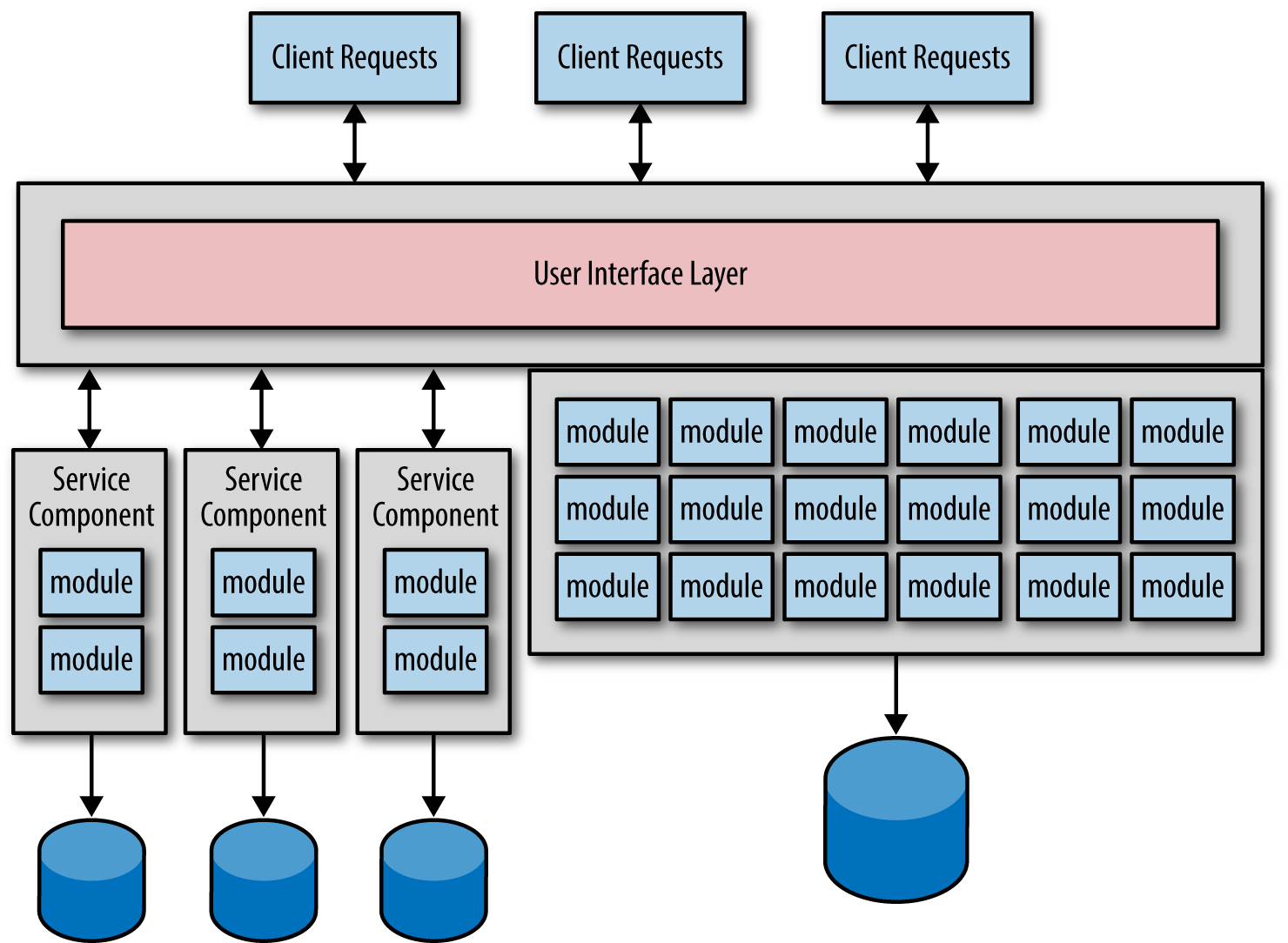
Figure 1-1. Service and data migration
Notice there are three services created from the monolithic application along with three separate databases. This is a natural migration process because you are creating that critical bounded context between each service and its corresponding data. However, problems start to arise with this common practice, thus leading you into the data-driven migration antipattern.
Too Many Data Migrations
The main problem with this type of migration path is that you will rarely get the granularity of each service right the first time. Knowing it is always a good idea to start with a more coarse-grained service and split it up further if needed when you learn more about the service, you may be frequently adjusting the granularity of your services. Consider the migration illustrated in Figure 1-1, focusing on the leftmost service. Let’s say after learning more about the service you discover it’s too coarse-grained and needs to be split up into two smaller services. Alternatively, you may find that the two leftmost services are too fine-grained and need to be consolidated. In either case you are faced with two migration efforts—one for the service functionality and another for the database. This scenario is illustrated in Figure 1-2.
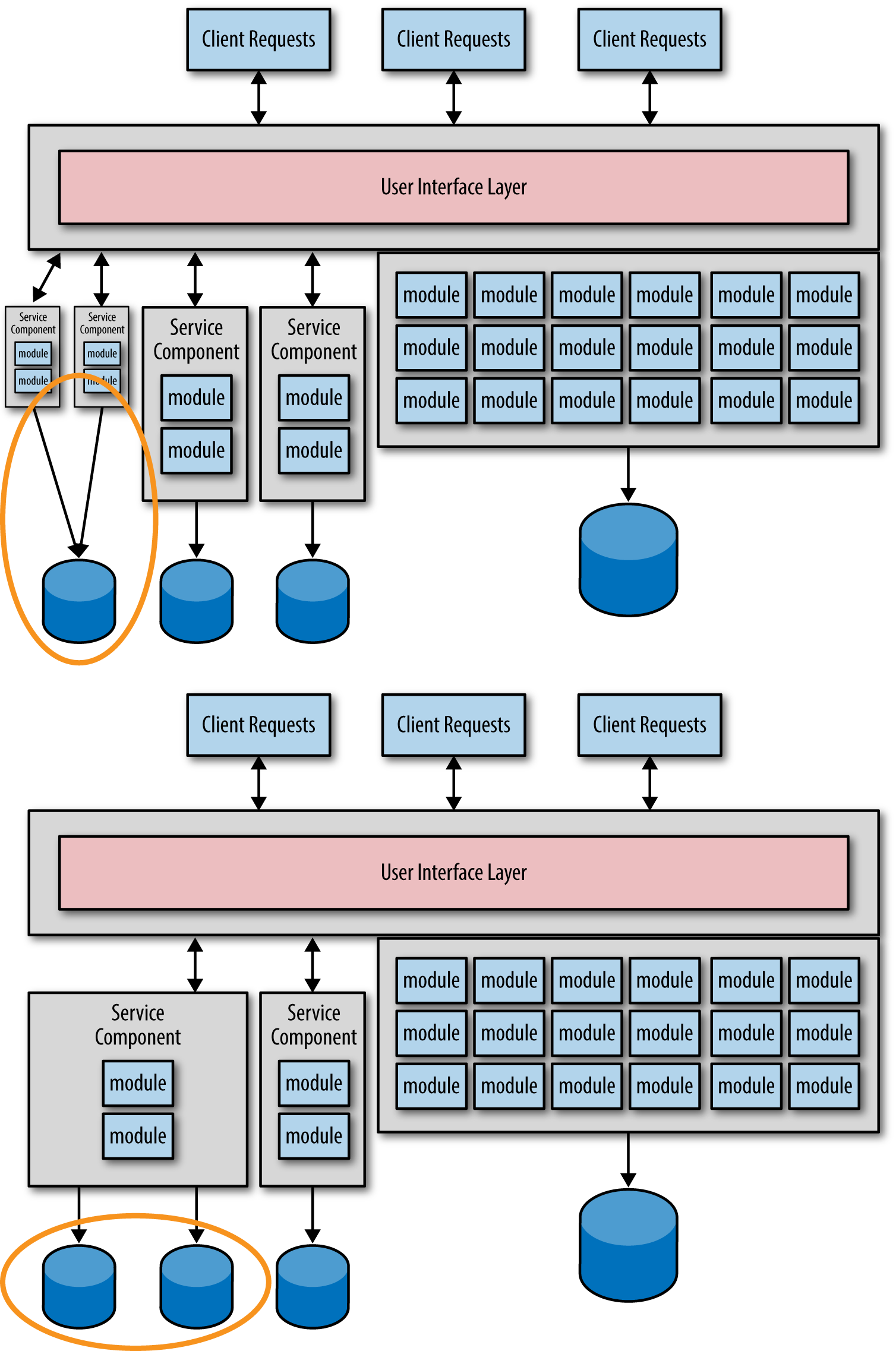
Figure 1-2. Extra data migration after service granularity adjustment
My good friend and fellow O’Reilly author Alan Beaulieu (Learning SQL) once told me “Data is a corporate asset, not an application asset.” Given Alan’s statement, you can gain an appreciation for the risk involved and the concerns raised with continually migrating data. Data migrations are complex and error-prone—much more so than source code migrations. Optimally you want to migrate the data for each service only once. Understanding the risks involved with data migration and the importance of “data over functionality” is the first step in avoiding this antipattern.
Functionality First, Data Last
The primary avoidance technique for this antipattern is to migrate the functionality of the service first, and worry about the bounded context between the service and the data later. Once you learn more about the service you will likely find the need to adjust the level of granularity through service consolidation or service splitting. After you are satisfied that you have the level of granularity correct, then migrate the data, thereby creating the much-needed bounded context between the service and the data.
This technique is illustrated in Figure 1-3. Notice how all three services have been migrated, but are still connecting to the monolithic data. This is perfectly fine for an interim solution, because now you can learn more about how the service is used and what type of requests will be handled by each service.
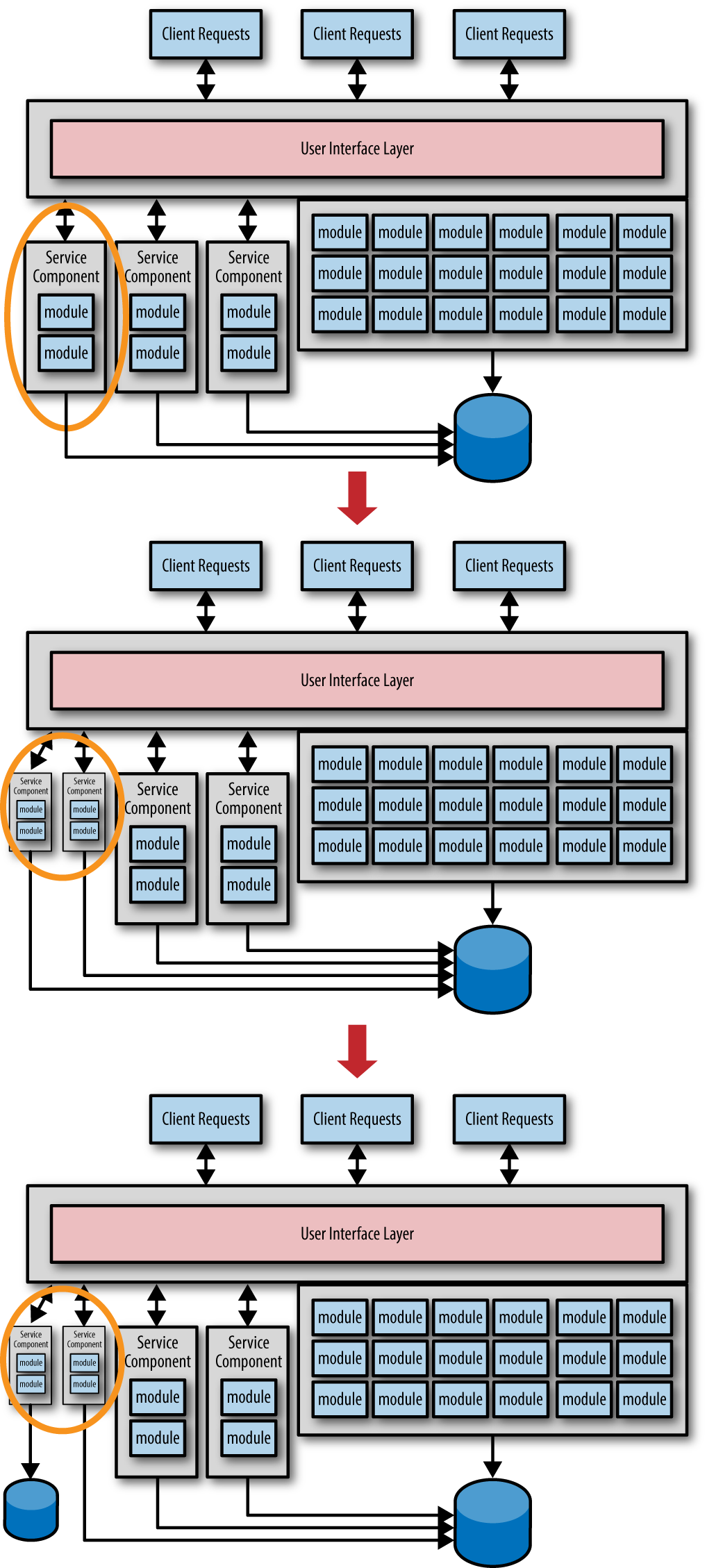
Figure 1-3. Migrate service functionality first, then data portion later
In Figure 1-3, notice how the service was found to be too coarse-grained and was consequently split into two smaller services. Now that the granularity is correct, the data can be migrated to create the bounded context between the service and the corresponding data. This technique avoids costly and repeated data migrations and makes it easier to adjust the service granularity when needed. While it is impossible to say how long to wait before migrating the data, it is important to understand the consequences of this avoidance technique—a poor bounded context. The time between when the service is created and the data is finally migrated creates a data coupling between services. This means that when the database schema is changed, all services using that schema must be coordinated from a change control and release standpoint, something you want to avoid with the microservices architecture. However, this tradeoff is well worth the reduced risk involved with avoiding multiple costly database migrations.