the macro problem with microservices
src: The macro problem with microservices - Stack Overflow - 2022-03-12
Abstract
Monoliths start to fall apart when scale and availability become requirements. The answer found was microservices. While microservices solved the scalability and availability issues that had been fundamentally blocking software growth, not all was well. Developers began to realize that microservices came with some serious drawbacks. With monoliths, developers write code that makes stateful changes in a binary way. Things happened or they didn’t. With microservices, the state of the world became distributed across different servers. Changing application state now required simultaneously updating different databases. This introduced a possibility that one DB would be successfully updated but the others could be down, leaving you stuck in an inconsistent middle state. But since services were the only answer to horizontal scalability, developers had no other path forward. While microservices were great for scaling, they came at the price of enjoyability and productivity for developers and reliability for applications.
Temporal is an open-source (MIT, no shenanigans), stateful, microservice orchestration runtime. Temporal aims to provide consistency, simplicity, and reliability for the application layer just like Docker, Kubernetes and serverless did for infrastructure. State preservation is a Temporal feature that uses event sourcing to automatically persist any stateful change in a running application. That’s to say if the computer running your Temporal workflow function crashes, the code will be resumed automatically on a different computer like the crash never happened. This even includes local variables, threads, and other application-specific state.
Microservices are great but the price developers and businesses pay in productivity and reliability to use them is not. Temporal aims to solve this problem by providing an environment that pays the microservice tax for the developer. State preservation, auto retrying failed calls, and visibility out of the box are just a few of the essentials Temporal provides to make developing microservices reasonable.
In just 20 years, software engineering has shifted from architecting monoliths with a single database and centralized state to microservices where everything is distributed across multiple containers, servers, data centers, and even continents. Distributed architectures have enabled developers to scale and meet the needs of an increasingly connected world. Distributing things also introduces a whole new world of problems, many of which were previously solved by monoliths.
In this article, I’ll discuss how we reached this point with a brief stroll through the history of networked applications. After that, we’ll talk about Temporal’s stateful execution model and how it attempts to solve the problems introduced by service-oriented architectures (SOA). In full disclosure, I’m the Head of Product for Temporal, so I might be biased, but I think this approach is the future.
A short history lesson
Twenty years ago, developers almost always built monolithic applications. The model is simple, consistent, and similar to the experience you get programming in a local environment.
Monoliths by nature rely on a single database, which means all state is centralized. A monolith can mutate any of its state within a single transaction, which means it yields a binary outcome—it worked or it didn’t. There is zero room for inconsistency. Therefore, monoliths provided a great experience for developers as they meant there was no chance of failed transactions resulting in an inconsistent state. In turn, this meant developers didn’t have to constantly write code to guess at the state of things.
For a long time, monoliths just made good sense. There weren’t a ton of connected users, which meant the scale requirements for software was minimal. Even the biggest of software giants were operating at a scale that seems minuscule today. There were a handful of companies like Amazon and Google that were running at “scale,” but they were the rare exception, not the rule.
People like software
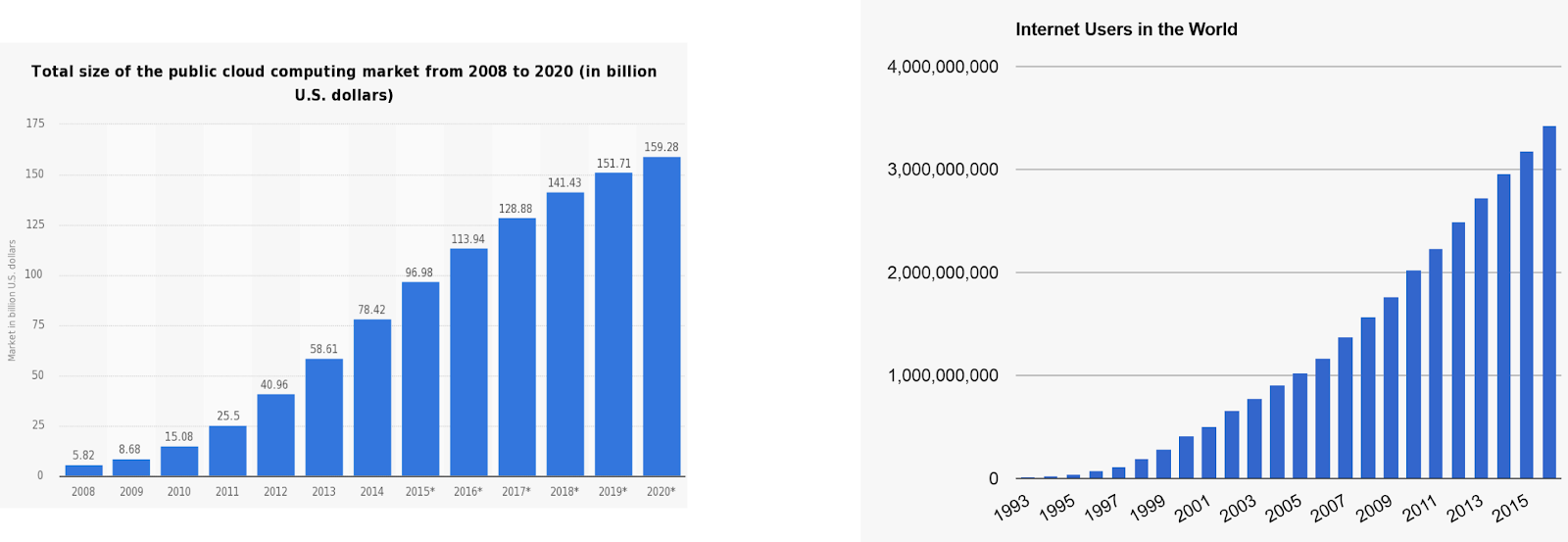
Over the last 20 years, demand for software wouldn’t stop growing. Today, applications are expected to serve a global market from day one. Companies like Twitter and Facebook have made 24/7 always-online table stakes. Software isn’t just powering things behind the scenes anymore, it’s become the end-user experience itself. Every company is now expected to have software products. Reliability and availability are no longer features, they are requirements.
Unfortunately, monoliths start to fall apart when scale and availability become requirements. Developers and businesses needed to find ways to keep up with rapid global growth and demanding user expectations. They began looking for alternative architectures that would alleviate the scalability issues they were experiencing.
The answer they found was microservices (well, service-oriented architectures). Microservices seemed great initially because they enabled applications to be broken down into relatively self-contained units that could be scaled independently. And because each microservice maintained its own state it meant your application was no longer limited to what fit on a single machine! Developers could finally build applications that met the scale demands of an increasingly connected world. Microservices also brought flexibility to teams and companies as they provided clear lines of responsibility and separation for organizational architectures.
No such thing as a free lunch
While microservices solved the scalability and availability issues that had been fundamentally blocking software growth, not all was well. Developers began to realize that microservices came with some serious drawbacks.
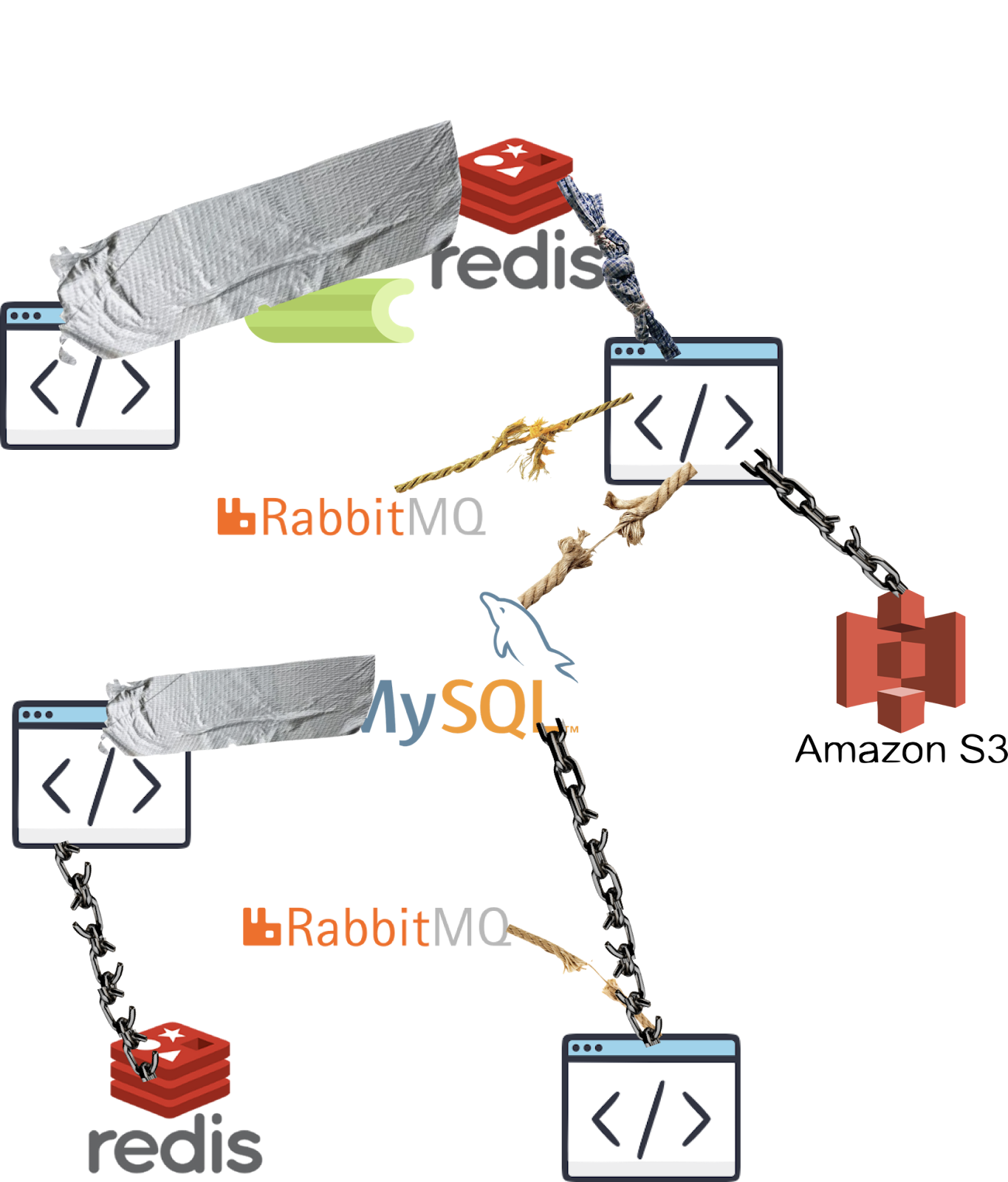
With monoliths, there was generally one database instance and one application server. And since a monolith cannot be broken down, there are only two practical options for scaling. The first option is vertical scaling which means upgrading hardware to increase throughput/capacity. Vertical scaling can be efficient but it’s costly and definitely not a permanent solution if your application needs keep growing. If you vertically scale enough, you eventually run out of hardware to upgrade. The second option is horizontal scaling, which in the case of a monolith means just creating copies of itself so that each serves a specific set of users/requests etc. Horizontally scaling monoliths results in resource underutilization and at high enough scales just plain won’t work. This is not the case with microservices, whose value comes from the ability to have multiple “types” of databases, queues, and other servers which are scaled and operated independently. But the first issue people noticed when they switched to microservices was that they had suddenly become responsible for a lot of different types of servers and databases. For a long time, this aspect of microservices wasn’t addressed and developers and operators were left to solve it themselves. Solving the infrastructure management issues that come with microservices is tough, which left applications unreliable at best.
Demand is the ultimate vehicle of change. As microservices adoption increased rapidly, developers became increasingly motivated to solve their underlying infrastructure problems. Slowly but surely, solutions started to appear, and technologies like Docker, Kubernetes, and AWS Lambda stepped in to fill the void. Each of these technologies greatly reduced the burden of operating a microservice infrastructure. Instead of having to write custom code that handles orchestrating containers and resources, developers could rely on tools to do the work for them. Now In 2020, we’ve finally reached a point where the availability of our infrastructure isn’t sabotaging the reliability of our applications. Great work!

Of course, we haven’t entered a utopia of perfectly stable software. Infrastructure is no longer the source of application unreliability; the application code is.
The other problem with microservices
With monoliths, developers write code that makes stateful changes in a binary way. Things happened or they didn’t. With microservices, the state of the world became distributed across different servers. Changing application state now required simultaneously updating different databases. This introduced a possibility that one DB would be successfully updated but the others could be down, leaving you stuck in an inconsistent middle state. But since services were the only answer to horizontal scalability, developers had no other path forward.
The fundamental problem with distributing state across services is that every call to an external service is an availability dice-roll. Developers can of course choose to ignore the problem in their code and assume every external dependency they call will always succeed. But if it’s ignored, it means one of those down-stream dependencies could take the application down without warning. As a result, developers were forced to adapt their existing monolith-era code to add checks that guessed to see if an operation failed in the middle of a transaction. In the below code, the developer has to constantly retrieve the last-recorded state from the ad-hoc myDB store to avoid potential race conditions. Unfortunately, even with this implementation there are still race conditions. If account state changes without also updating myDB, there is room for inconsistency.
public void transferWithoutTemporal(
String fromId,
String toId,
String referenceId,
double amount,
) {
boolean withdrawDonePreviously = myDB.getWithdrawState(referenceId);
if (!withdrawDonePreviously) {
account.withdraw(fromAccountId, referenceId, amount);
myDB.setWithdrawn(referenceId);
}
boolean depositDonePreviously = myDB.getDepositState(referenceId);
if (!depositDonePreviously) {
account.deposit(toAccountId, referenceId, amount);
myDB.setDeposited(referenceId);
}
}Unfortunately, it’s impossible to write bug-free code, and generally, the more complex the code, the higher likelihood for bugs. As you might expect, code that deals with the “middle’ is not only complex but also convoluted. Some reliability is better than none, so developers are forced to write this inherently buggy code to maintain the end-user experience. This costs developers time and energy and costs their employers lots of money. While microservices were great for scaling, they came at the price of enjoyability and productivity for developers and reliability for applications.
Millions of developers are wasting time every day reinventing one of the most reinvented wheels, reliability boilerplate code. Current approaches for working with microservices simply do not reflect the reliability and scalability requirements of modern applications.
Temporal
So, now comes the part where we pitch you our solution. To be clear, this isn’t endorsed by Stack Overflow. And we are not saying it’s perfect yet. We want to share our ideas and hear your thoughts. What better place to get feedback on improving code than Stack?
Until today, there was no solution that enabled developers to use microservices without running into these issues I laid out above. You could test and simulate failure states, writing code to anticipate breakdowns, but these issues would still happen. We believe Temporal solves this problem. Temporal is an open-source (MIT, no shenanigans), stateful, microservice orchestration runtime.
Temporal has two major components: a stateful backend layer which is powered by the database of your choice and a client-side framework in one of the supported languages. Applications are built using a client-side framework and plain old code which automatically persists state changes to the backend while your code runs. You are free to use the same dependencies, libraries, and build chains that you would rely on when building any other application. To be clear, the backend itself is highly distributed so this isn’t a J2EE 2.0 situation. In fact, the distributed nature of the backend is exactly what enables nearly infinite horizontal scaling. Temporal aims to provide consistency, simplicity, and reliability for the application layer just like Docker, Kubernetes and serverless did for infrastructure.
Temporal provides a number of highly-reliable mechanisms for orchestrating microservices but the most important is state preservation. State preservation is a Temporal feature that uses event sourcing to automatically persist any stateful change in a running application. That’s to say if the computer running your Temporal workflow function crashes, the code will be resumed automatically on a different computer like the crash never happened. This even includes local variables, threads, and other application-specific state. The best way to understand how this feature works, is by an analogy. As a developer today, you’re most likely relying on version control SVN (it’s the OG Git) to track the changes you make to your code. The thing about SVN, is that it’s not snapshotting the comprehensive state of your application after each change you make. SVN works by only storing new files and then references existing files avoiding the need to duplicate them. Temporal is sort of (again rough analogy) like SVN for the stateful history of running applications. Whenever your code modifies the application state, Temporal automatically stores that change (not the result) in a fault-tolerant way. This means that Temporal cannot only restore crashed applications, but also roll them back, fork them and much more. The result is that developers no longer need to build applications with the assumption the underlying server can fail.
As a developer, this feature is like going from manually saving (ctrl-s) documents after every letter you type to autosave in the cloud with Google Docs. It’s not just that you’re not manually saving anymore, there’s no longer a single machine associated with that document. State preservation means developers write far less of the tedious, boilerplate code that was initially introduced by microservices. It also means that the ad-hoc infrastructure — like standalone queues, caches, and databases — is no longer needed. This reduces ops burden and the overhead of adding new features. It also makes onboarding new hires much easier because they no longer need to ramp up on the messy and domain-specific state management code.
State preservation also comes in another form: “durable timers.” Durable timers are a fault-tolerant mechanism that developers leverage through the Workflow.sleep command. In general Workflow.sleep functions exactly like the language native sleep command. But with Workflow.sleep you can safely sleep for any period of time, no matter how long. There are many Temporal users with workflows that sleep for weeks or even years. To achieve this, the Temporal service persists durable timers in the underlying datastore and tracks when the corresponding code needs to be resumed. Again, even if the underlying server crashes (or you just shut it down), the code will be resumed on an available machine when the timer is intended to fire. Sleeping workflows do not consume resources so you can have millions of sleeping workflows with negligible overhead. This might all seem very abstract so here is an example of working Temporal code:
public class SubscriptionWorkflowImpl implements SubscriptionWorkflow {
private final SubscriptionActivities activities =
Workflow.newActivityStub(SubscriptionActivities.class);
public void execute(String customerId) {
activities.onboardToFreeTrial(customerId);
try {
Workflow.sleep(Duration.ofDays(180));
activities.upgradeFromTrialToPaid(customerId);
while (true) {
Workflow.sleep(Duration.ofDays(30));
activities.chargeMonthlyFee(customerId);
}
} catch (CancellationException e) {
activities.processSubscriptionCancellation(customerId);
}
}
}Outside of state preservation, Temporal offers a suite of mechanisms for building reliable applications. Activity functions are invoked from within workflows, but the code running inside an activity is not stateful. Although they aren’t stateful, Activities come with automatic retries, timeouts, and heartbeats. Activities are very useful for encapsulating code that has the potential to fail. For example, say that your application relies on a bank’s API that is often unavailable. With a traditional application, you would need to wrap any code that calls the bank API with numerous try/catch statements, retry logic, and timeouts. But if you call the bank API within an activity, all of these things are provided out of the box, which means if the call fails, the activity will be retried automatically. Retries are great, but sometimes the unreliable service is one you own and you prefer to avoid DDoSing it. For this reason, activity calls also support timeouts, which are backed by durable timers. This means you can have activities wait hours, days, or weeks between retry attempts. This is especially great for code that you need to succeed but aren’t concerned about how fast it happens.
Caption: This video explains the Temporal programming model in 2 minutes
Another powerful aspect of Temporal is the visibility it provides into running applications. The visibility API provides a SQL-like interface to query metadata from any workflow (running or otherwise). It’s also possible to define and update custom metadata values from directly within a workflow. The visibility API is great for Temporal operators and developers, especially when debugging during development. Visibility even supports applying batch actions to the result of a query. For example, you can send a kill signal to all workflows that match your query of creation time > yesterday. Temporal also supports a synchronous-fetch feature which enables developers to fetch the value of local workflow variables in running instances. It’s sort of like if the debugger in your IDE worked on production apps. For example, it’s possible to get the value of greeting in a running instance of the below code:
public static class GreetingWorkflowImpl implements GreetingWorkflow {
private String greeting;
@Override
public void createGreeting(String name) {
greeting = "Hello " + name + "!";
Workflow.sleep(Duration.ofSeconds(2));
greeting = "Bye " + name + "!";
}
@Override
public String queryGreeting() {
return greeting;
}
}Conclusion
Microservices are great but the price developers and businesses pay in productivity and reliability to use them is not. Temporal aims to solve this problem by providing an environment that pays the microservice tax for the developer. State preservation, auto retrying failed calls, and visibility out of the box are just a few of the essentials Temporal provides to make developing microservices reasonable.