secure by design - handling failures securely
Abstract
- Separating business exceptions and technical exceptions is a good design strategy because technical details don’t belong in the domain.
- You shouldn’t intermix technical and business exceptions using the same type.
- It’s a good design practice to never include business data in technical exceptions, regardless of whether it’s sensitive or not.
- You can create more secure code by designing for failures and treating failures as normal, unexceptional results.
- Availability is an important security goal for software systems.
- Resilience and responsiveness are traits that add security by improving the availability of a system.
- You can use design patterns like circuit breakers, bulkheads, and timeouts to design for availability.
- Repairing data before validation is dangerous and should be avoided at all costs.
- You should never echo input verbatim.
Using exceptions to deal with failure
Throwing exceptions
3 reasons for throwing exceptions in an application:
- domain rule violations ⇒ business exceptions
- framework violations ⇒ technical exceptions
- technical violations ⇒ technical exceptions
Tip
Be careful using
FindFirstas it implies you don’t care which element you choose as long as it exists.A better solution is to use
reduceto state the uniqueness assumption explicitly and to fail if multiple elements are found.Example:
public static void main(String[] args) {
Optional<String> result = Stream.of("foo", "bar")
.filter("foo"::equals)
.reduce((a, b) -> {
throw new IllegalStateException("Multiple elements found");
});
System.out.println(result.orElse("not found"));
}Handling exceptions
You should separate business and technical exceptions by explicitly defining exceptions that are important for the business.
Separating business exceptions and technical exceptions clearly makes the code less complex and helps prevent accidental leakage of business information.
public Balance accountBalance(Customer customer, AccountNumber accountNumber) {
try {
return repository.fetchAccountFor(customer, accountNumber).balance();
// handles explicitly without parsing the internal message
} catch (AccountNotFound e) {
return Balance.unknown(accountNumber);
// catches all unhandled business exceptions
} catch (AccountException e) {
// signals that an unhandled domain exception has been deteced and that the transaction should be aborted
throw new IllegalStateException("Unhandled domain exception: " + e.getClass().getSimpleName());
}
}Dealing with exception payload
There are two parts of an exception that are of special interest when analyzing failures: the type and the payload.
On one hand, you need enough information to facilitate failure analysis, on the other hand, you want to prevent data leakage. How does this affect the design?
To start with, you need to recognize that almost any business data is potentially sensitive in another context. This means it’s good design practice to never include business data in technical exceptions, regardless of whether it’s sensitive or not.
You need to make sure to provide only information that makes sens from a technical perspective, for example “Unable to connect to database with ID XYZ”, instead of the account number and customer data that caused the failure.
You also need to identify sensitive data in your domain and model it as such.
Handling failures without exceptions
You can treat negative results as something exceptional by throwing an exception if the condition is not fulfill, but there is an alternative way to view failures: by designing for failures.
By designing failures as expected and unexpectional outcomes, you completely eliminate the use of exceptions as part of the domain logic. By doing so, you’re able to either avoid or reduce the risk of many of the security issues you faced when designing your code with exceptions.
Security benefits of designing failures as expected outcomes:
- ambiguity between domain exceptions and technical exceptions: domain exceptions are completely removed
- exception payload leaking into logs: failures aren’t handled by generic error-handling code, and, therefore, the data the playload carries doesn’t accidentally slip into error logs
- inadvertently leaking sensitive information: failures are handled in a context that has knowledge about what’s sensitive and wha’ts not and know how to handle sensitive data properly
The only exceptions that can still occur are those caused by either bugs or a violation of an invariant.
Designing for availability
Resilience
A system that’s resilient is designed to stay functional even during high stress. Stress for a system can be caused by both internal failures (errors in code or failing network communication) and external factors (e.g. high traffic load).
Stress can cause a resilient system to slow down or run with reduced functionality, and parts of the system can crash, but the system as a whole will stay available and it’ll recover once the stress it’s been put under disappears.
Responsiveness
When the system is available, but responds slowly, another system calling the slow system eventually gets a response, but it can take an unacceptably long time. From the caller’s point of view, the system under load can be considered to be unusable. This is where responsiveness cimes in as an important trait when discussing availability.
Tip
It’s far better to answer quickly with an error saying that the system is unable to accept any more requests than to have the caller sit around waiting for an answer that might never come. Any answer is better than no answer, even if that answer is rejecting the request.
Circuit breakers and timeouts
This pattern is handy for dealing with failures in a way that promotes system resilience, responsiveness, and overall availability, and therefore also security.
A circuit breaker in software can isolate failures and prevent an entire system from crashing.
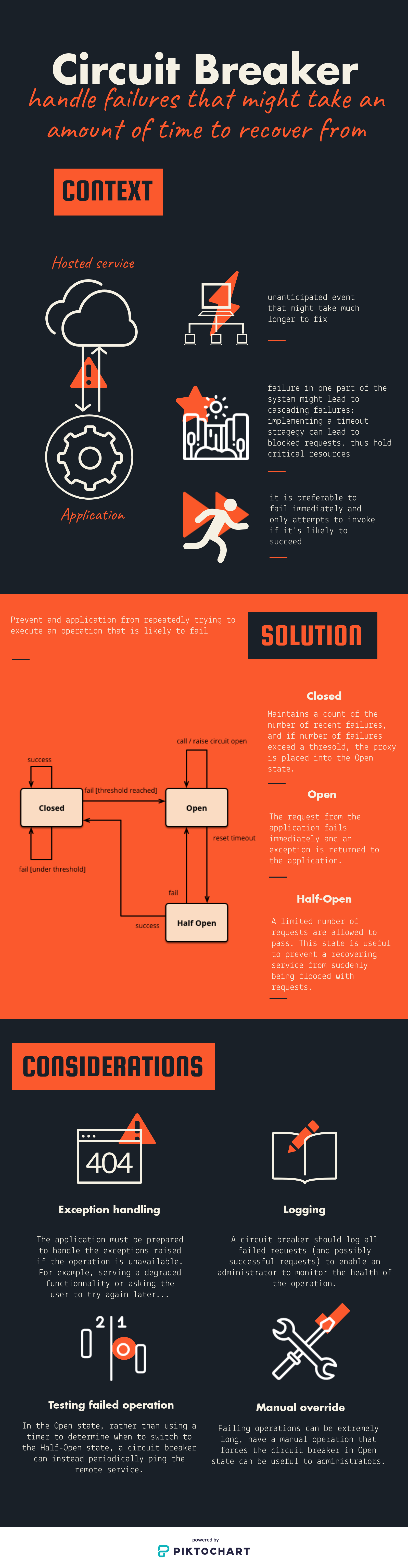
Tip
Always specify a timeout, otherwise, the number of systems that have turned into unresponsive memory hogs due to unresponsive integration points.
The way the system should behave if a request fails is usually a decision that affects your domain logic, and, therefore, it’s a decision that needs to be made together with the domain experts.
Bulkheads
Design pattern you can use to efficiently prevent failures in one part of a system from spreading and taking down the entire system.
Location level
A system’s availability can be improved by running the system on servers distributed over multiple geographical locations.
Infrastructure level
Separating load and service instances by business functionality so they don’t affect each other.
SOA are typically a good fit applying bulkheads in this manner.
Code level
A common example of the bulkhead pattern applied on a code level is thread pools. A thread pool lets you set a limit on how many threads is the code can create. Regardless of how much work needs to be processed, there’ll never be more threads than are allowed in the pool.
Queues are another code construct you can use in order to isolate failures in your code base. Queues are often used together with thread pools. If all the threads in the pool are busy, additional work can be put in a queue. As soon as a thread becomes available in the pool, the queue can be queried for work to be processed. If the queue is full at some point, the application can refuse to accept any new work.
Handling bad data
Using contracts to protect against bad state and input that doesn’t meet the defined preconditions certainly tightens the design and makes assumptions explicit, but applying contracts often leads to discussions about repairing data before validation to avoid unnecessary rejection. Unfortunately, this approach is extremely dangerous because it can expose vulnerabilities and result in a false sense of security.
Another issue is the urge to echo input verbatim in exceptions and write it to log files when a contract fails. From a security perspective, it’s a ticking bomb waiting to explode (e.g. log full HTTP request that may contains credentials).
If you are unsure, play it safe and avoid doing so completely.