State of data engineering 2022
A year has passed since we shared the State of Data Engineering 2021. And since we released that article last May, not much has changed in the data landscape. In fact, we had discussions internally about whether we should even do an update for 2022.
We kid.
It was another year worthy of its own prime-time drama, and we’re back to share our updated, digestible snapshot of it all!
What has changed this year?
The major theme we saw play out in the past year is consolidation. Companies expanding their scope to break into new categories, or simply coming into existence with the value-prop of replacing several existing tools in the data stack.
Let’s take a look at the updated diagram, this year in a higher resolution!
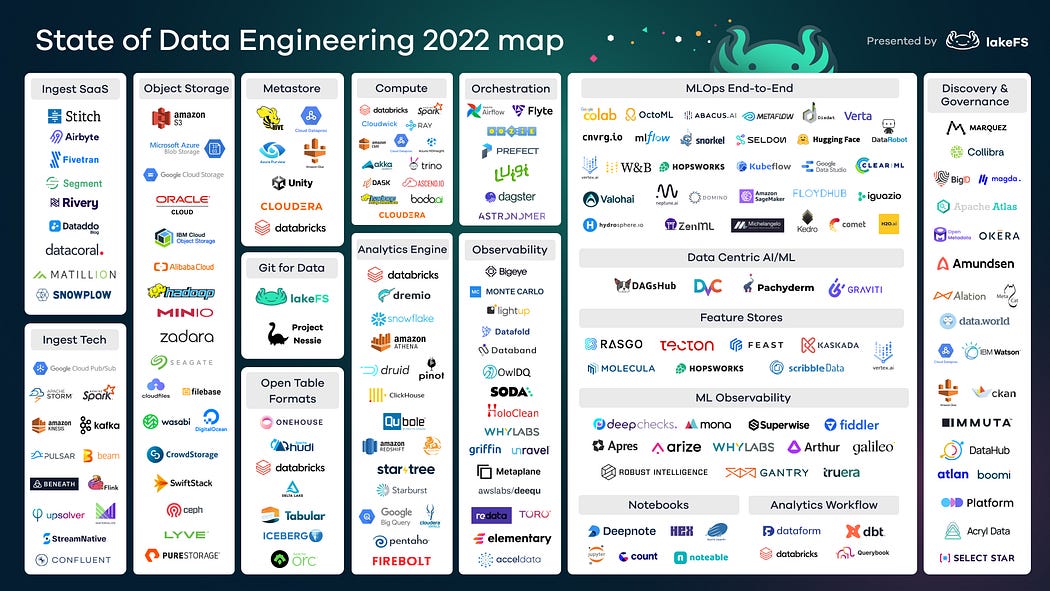
Click here for a full-sized, zoom-able version of the State of Data Engineering 2022 Map.
{kind=link}
Let’s cover in section in more detail, shall we?
Ingestion
This layer includes streaming technologies and SaaS services that provide pipelines from operational systems to data storage.
The evolution worth mentioning here is the dramatic rise of Airbyte. Founded in 2020 and pivoting to its current offering only towards the end of that year, Airbyte is an open-source project used today by over 15,000 companies. The community counts over 600 contributors. It’s rare to see such exponential growth in usage and community.
Airbyte has just launched its commercial offering and expanded to reverse ETL (a category we don’t cover in our diagram) by acquiring Grouparoo, an open source for reverse ETL connectors. We believe reverse ETL to be a very different product then ETL, as it requires integrating the data into the operational systems in a way that benefits the users’ workflow within that system.
Curious to see how things turn out.
Data Lakes
In 2021, we included data warehouses and lakehouses as part of the data lake layer. But this year, we decided to keep the data lake category solely for the object storage technologies used as data lakes. We moved all warehouses and lakehouses to the analytics engines category.
Why? Most of the architectures data engineers deal with today are complex enough to include both object storage and an analytics engine. So you either only need an analytics database (in which case you don’t have a data lake but a data warehouse that serves as the analytics engine) or you need both. And when you need both, you usually perform some of the analysis over the object storage and some over the analytics engine. That’s why they need to work very well together.
This dependency occurs at different layers. Large data sets would be managed in your object storage while artifacts and serving layer datasets would be stored within analytics engines and databases. The idea that one of them would conquer the other is something that we’re not seeing in architectures around us.
What we see in reality is these solutions co-exist. There are several reasons behind this architecture and one of them is definitely cost considerations. Querying a massive volume of data in Snowflake or BigQuery is expensive. So instead of having analytics databases managing your entire lake, you manage everything you can in object storage with cheaper compute over it and leave all the must-haves for the analytics engines.
We consider a lakehouse to be an analytics engine (although in Databricks it includes both the data lake and analytics engine). This architecture features an optimized version of Spark SQL to create an analytics engine over the Delta table format. This delivers the increased performance and costs expected from an analytics engine.
The same rule applies to Dremio over Iceberg, or to Snowflake supporting Iceberg as external tables to its database.
Metadata Management
A lot of things are happening in the metadata space! The two layers of metadata, this one and the organizational one at the top of our chart, are becoming a focus in many organizations.
Reviewing the evolution of our challenges as scalable data practitioners, we have spent the past decade innovating around storage and computers — all to make sure they support the scale of data.
Today, we face mostly manageability problems and can solve them by producing and managing metadata. This layer includes different aspects of metadata, let’s go through them.
Open Table Formats
We’ve seen interesting advancements in open table formats in the past year. They’re becoming a standard for holding structured data in a data lake.
A year ago, Delta Lake was a Databricks project with an actual commercial product called Delta. Then this year, we have Apache Hudi commercialized by Onehouse and Apache Iceberg commercialized by Tabular. Both companies were founded by the creators of these open-source projects.
So, the entire space went from being open-source to fully backed up by commercial entities. This brings a question mark to how much influence other players would have on the open-source project now that there’s a commercial interest behind it.
Since all three open-source projects are part of the apache/Linux Foundation, the risk to the community is low. This doesn’t seem to calm the passionate dispute between the creators and fans of all these three projects over who is “really” open source and who has the best solution. Netflix will soon jump on this story as excellent material for a drama show. 🙂
Metastore’s Future Is Still in the Dark…
We’re seeing Hive Metastore being pulled out of architectures where it’s possible to replace it with open table formats. Not all organizations are making full use of Metastore capabilities, and if their only use case was virtualizing tables then open table formats and the commercial offerings around them provide a good option. Other use cases for Metastore have yet to receive a better alternative solution.
Git for data
The concept of Git for data is taking hold in the community. dbt is encouraging analysts to use best practices over different versions of data (dev, stage and production), though does not support the creation and maintenance of those data sets in data lakes.
There is a growing demand from DataOps teams to provide cross-organizational data version control to manage data sets that have different revisions over time. A few examples for different revisions to a data set are: recalculation, necessary for algorithms and ML models, or of backfills from operational systems as often happens in BI, or deletion of a subset due to regulations such as the right to be forgotten under GDPR.
This trend is clear from the dramatic growth in the adoption of lakeFS and its community, which I’ve witnessed first-hand. lakeFS serves both structured and unstructured data operations, shining in cases where both exist.
Unfortunately, public data on usage for Dremio’s Project Nessie is hard to come by. Interestingly, it is also available as a free service named Arctic. This is likely a strategic decision made to compete with Tabular.
Compute
We applied some changes to the compute layer this year to reflect the ecosystem better. First, we removed virtualization as a category altogether. It doesn’t seem to be catching on at the moment.
We then split the compute engines into two categories: distributed compute and analytics engines. The main difference between them is how opinionated these tools are regarding their storage layer.
While distributed compute includes compute engines that aren’t opinionated about storage, the analytics engines category contains compute engines (distributed or not) that are opinionated.
Distributed Compute
The general distributed compute engines allow engineers to distribute anything that is SQL or any other code. Sure, they might be opinionated about the programming language, but they will carry out a general distribution over (usually) federated data. This could be data stored across many formats and sources.
The two interesting additions to the distributed compute category are Ray and Dask.
Ray is an open-source project that allows engineers to scale any compute-intensive Python workload, used mainly for machine learning. Dask is also a distributed Python engine based on Pandas.
You might have thought that Spark would be the distributed engine ruling the scene with no competition in sight. So, it’s pretty exciting to witness the rise of new technologies gaining traction in this category.
Analytics Engines
The analytics engines category includes all data warehouses such as Snowflake, BigQuery, Redshift, Firebolt, and the good old PostgreSQL. It also contains lakehouses like Databricks lakehouse, Dremio, or Apache Pinot. All are very opinionated about the data format they support to provide better performance to their querying engines.
Since all analytics engines use the data lake as their deep storage or storage, it’s worth mentioning that Snowflake now supports Apache Iceberg as one of the external table formats that can be read by Snowflake directly from the lake.
Orchestration and Observability
This is a new layer populated by existing categories. Orchestration tools were part of the metadata layer last year, but we moved it over to the compute engine where it really belongs — it’s about orchestrating pipelines across compute engines and data sources.
Together with orchestration, we get observability tools that also grew a lot during 2021 to support more data sources resulting in any compute engine.
Orchestration
Did anything eye-catching happen around orchestration? Airflow is still the biggest open-source product. Astronomer has backed it for a few years already and since the company jumped on the cloud bandwagon, it’s now directly competing with cloud providers on the managed Airflow front.
Another very interesting move by Astronomer is the acquisition of Datakin which provides data lineage. This makes one wonder — what happens when an orchestration tool has lineage capabilities?
This, in theory, could help data teams build safer, more resilient pipelines. By knowing which datasets depend on missing, corrupt or low quality data, it makes impact analysis considerably easier by tying together the logic (managed by orchestration tools) and their output (managed in lineage tools). Whether this materializes into an integral part of the orchestration ecosystem is to be seen.
Observability
The observability category, established by Monte Carlo data, is also led by it. Monte Carlo’s frequent fund raising is an indication of its products’ rapid adoption in the market. The product keeps evolving, offering more integrations, for example, the databricks ecosystem, and additional observability and root cause analysis features. It is this success that is probably driving the growth of the category, at least from the perspective of the number of companies exploring this front today. Several companies were founded or went out of stealth in 2021, most interesting is Elementary, another open source project out of YC
Data Science + Analytics Usability
This layer is meant for the users of data architectures created through the former layers: data scientists and analysts who unlock insights from data. We split this category into three subcategories:
- End-to-end MLOps tools,
- Tools based on the data-centric ML approach,
- ML observability and monitoring.
End-to-end MLOps tools
When I set out to review this space, someone told me I should name the category: “Prepare to be disappointed.” While the category includes great tools, none of them is really end-to-end. They offer a good solution to certain steps in the ML process but lack at their offering for other aspects of the ML pipeline.
Still, the approach of offering an end-to-end solution was popular in 2021. Several mission-specific tools entered the path to become an end-to-end offering. Examples include Comet, Weights & Biases, Clear.ml and Iguazio.
Data-centric ML
This subcategory doesn’t escape the end-to-end trap either, but the tools listed in it take on a different approach to the functionality they provide. They put the data itself and its management at the center of their missions.
The two new joiners to this space are Activeloop and Graviti. They were built by experienced data practitioners who understand the criticality of data management to the success of any data operation. We share this sentiment at lakeFS.
A unique approach is taken by DagsHub, which provides an E2E solution that is data-centric but bases its offering on open source solutions. They excel at each of the ML lifecycle phases, providing their unique usability and ease of integration touch. In such a confusing space, this is a solid approach to get a good end-to-end solution that also delights users. We’re watching the company with anticipation….
ML observability and monitoring
This subcategory includes tools focusing on the monitoring and observability of model quality. Very much like the data observability category, this space is growing and gaining momentum. In early 2022 Deepchecks went open source, and had quickly gained traction, contributors, and partners.
Notebooks
In the category of notebooks, we see Hex getting more traction and validation by investment from both Databricks and Snowflake. Hex offers more orchestration capabilities within its notebook. The same is true for Ploomber which emerged to offer orchestration capabilities to Jupyter.
The category of tools meant for analysts established itself over the past year and gained some competition. dbt proved itself as a standard for analysts and, in 2021, it released integrations with the scalable data engineering stack, including object storage, HMS, and the Databricks offering. While collaborating with the ecosystem, in 2021 Databricks launched the GA of its ‘live tables’ product, which is in direct competition with dbt.
Catalogs, Permissions and Governance
My sense of the ecosystem is that the need for a data catalog is now clear to companies of all sizes, and we will see it become a standard. Commercial offerings based on open-source projects show good levels of adoption.
Meanwhile, long-time providers for enterprise solutions, Alation and Collibra, continue to expand their offerings. And the security and permissions supplier BigID is attempting to offer a catalog as well.
Immuta stays persistent in its focus on data access control, and its unique technology is now compatible with additional data sources. To accelerate its growth, the company raised $90 million in series D funding back in mid-2021.
Conclusion
While the number of companies in the space keeps growing, we can see signs of consolidation in product offerings across several of these categories.
MLOps is trending towards end-to-end, notebooks are going into orchestration, and orchestration is turning towards lineage and observability. At the same time, we see open table formats going into the Metastore functionality. And in the governance layer, security and permission tools go into catalogs and the other way around…
Are those signs of a (still) limited market, maybe in MLOps? Does this consolidation reflect the need for differentiation due to fierce competition (which may be the case in orchestration)? Or is it an opportunity to fill a void that may be the case with open table formats or data-centric ML? Maybe it’s all because users want to use fewer tools that do more?
I’m going to leave these questions open in hope to initiate a discussion about the state of data engineering in 2022.
What other projects are gaining steam in 2022? Which tools are on their way to becoming de facto standards in the industry? Share your thoughts in the comments section!