Virtual Threads are something that I am excited about. It is a long-awaited feature in the language and we already had a few attempts for implementing it in the past, but at last, it is here and it is already merged into Java 19. This means that it is going to be included as a preview feature and we will be able to use it as soon as JDK 19 comes out.
While I was reading about this, I had to go through lots of posts and videos. The majority of the content on virtual(green) threads is written by non-java developers, why is that? Green threads are something quite new to the Java world, most Java applications use regular (platform) threads and are rarely exposed to this concept. Java is one of the most popular languages and is the only one among them that doesn’t support any form of async/await without the help of a third-party library (we will get to those soon).
In the very early versions of Java, when the multithreading API was designed, Sun Microsystems were faced with a dilemma: should we use User Mode threads or map the Java thread one-to-one with the OS thread? All benchmarks back then showed that User Mode threads were severely inferior, increasing memory consumption without giving much in return. However, this was benchmarked 20 years ago and things were quite different back then. We didn’t have such high load requirements and the Java language was still not very mature. Now the situation is different and we had a few attempts at introducing user mode threads into the language. For example Fibers.
Unfortunately, because they were implemented as a separate class, it was very hard to migrate your whole codebase to it, and eventually, they disappeared and never got merged into the language.
Project Loom
There are several Java projects that have very specific task to achieve. Those are for example Valhalla, Panama, Amber, and of course Loom. Loom’s goal is to overhaul the concurrency model of the language. They aim to bring virtual threads, structured concurrency, and a few other smaller things (for now).
Few words on the Java Concurrency model
The way threads are implemented in the JVM is considered one of the best, even by non-Java devs. We have excellent thread debugging, you get thread dumps, breakpoints, memory inspection, and much much more. You can even use the JFR API to define custom metrics for your threads.
The Thread class is the way Java gives you access to the OS Thread API. Most of the operations performed in this class make system calls. In production we rarely use the Thread directly, we use the Java concurrency package with the Thread Pools, Locks along with other nice things. Java has great built-in tooling for multithreading.
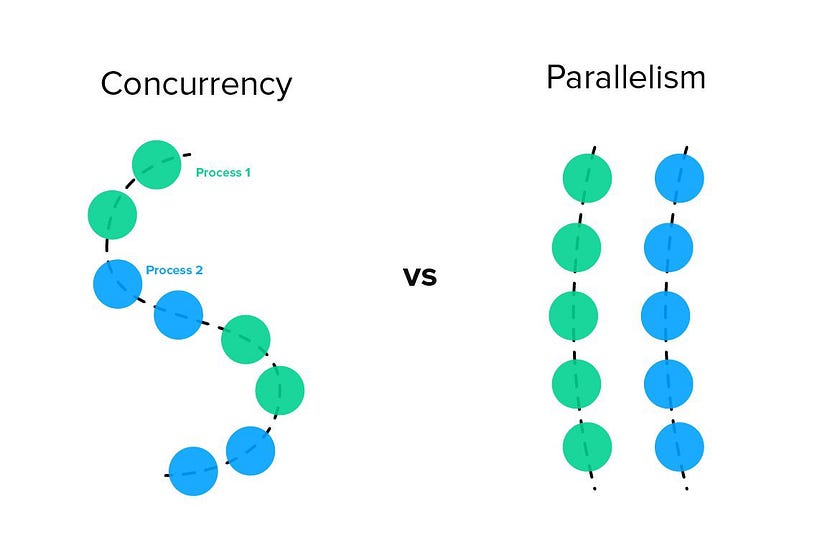
Concurrency and parallelism
Before we continue with the interesting stuff, we have to get this out of the way. Concurrency and parallelism are two things that are very often mixed together and confuse people.
Parallel means that two or more tasks are executed at the same time. This is possible only if the CPU supports it. We need multiple cores to achieve parallelism. However modern CPUs are always multi-core and single-core CPUs are mostly outdated and no longer widely used since they are greatly outperformed by the multi-core ones. This is because modern applications are designed to utilize multiple cores and they always need a few things to be done simultaneously.
Concurrency means that tasks are managed at the same time. For example, JavaScript is a single-threaded language, everything that has to happen at the same time happens concurrently. One Thread manages all of the tasks that the code spawns. JS uses async/await to do this, we will discuss other ways of achieving concurrency shortly.
From the OS perspective, the CPU has to handle the threads of multiple processes. The number of threads is always higher than the number of cores which means the CPU has to perform a context switch. Briefly explained every thread has a priority and can either be idle, working or waiting for CPU cycles. The CPU has to go through all of the threads that are not idle and distribute its limited resources based on priority. Furthermore, it has to ensure that all threads with the same priority get the same amount of CPU time, otherwise, some applications might freeze. Every time a core is given to a different thread the currently running thread has to be frozen and its register state preserved. On top of all of this, it has to track if some of the idle threads haven’t woken up. As you can see this is quite a complicated and expensive operation and we as developers should try to minimize the number of threads we use. In the ideal case the thread count should stay close to the CPU core count, this way we will be able to minimize the CPU context switching.
Modern Java server concurrency problems
The cloud space is growing more and more and with it the load and resource requirements. Most of the enterprise servers (the ones with the biggest load) are written in Java, so it comes to Java to solve the load problem. So far it is doing a great job, judging by the fact that it is still the most popular language for servers, but this doesn’t mean it’s perfect.
The usual way we handle requests is by dedicating a platform thread to them, this is the “Thread per request model”. The client requests something, while we fetch the data or do the processing this thread is taken and can’t be used by anyone else. Servers start and allocate a predefined number of threads (for example 200 for Tomcat). They are placed in a thread pool and await requests. Their initial state is called “Parked”, while they are in this state they don’t take CPU resources.
This is very easy to write, understand and debug, but what if the client requests something that performs a blocking call? Blocking calls are operations that wait for a third-party call to finish, for example, SQL query, request to a different service, or simply IO operation to the OS. When a blocking call happens the thread has to wait. While it is waiting the thread is not usable and the CPU has to manage it since it is not idle. This increases the context switches. Servers limit the thread count, higher thread counts might increase the throughput but they will dramatically slow the request processing. It’s a fine balance that we have to keep in mind and manage. People often ask, “Why not just spawn 10k threads, and process 10k requests at the same time”, although this is possible the OS won’t stop you, heck you can even spawn 1 million Threads with the proper configuration, there are benchmarks that show 80% CPU utilization purely for context switching after 3–4k threads on popular CPUs and keep in mind that the OS also needs CPU to run and manage other processes.
To solve our scalability problems, we often just scale and spawn multiple nodes of the server. This works, we can now handle as many requests as we like if we pay enough to our cloud vendor, but with cloud technologies, one of the main driving factors is reducing the cost of operation. Sometimes we can’t afford the extra spending and we end up with a slow and barely usable system.
Concurrency Models
Concurrency to the rescue! Let’s talk about a few concurrency models adopted in other languages
Callbacks
Callbacks are a simple and powerful concept. They are objects that are passed as parameters to other functions or procedures. The parent function passes the callback to the child function, the child can then use the callback to notify the parent function of certain events, for example, “I have completed my task”. This is a way to achieve concurrency on a single thread. Callbacks form a stack trace that can make debugging easier. They are good when the nesting is one or two levels but quickly get out of hand when you need to build a more complicated callback chain. Currently, they are mostly used as building blocks for other concurrency models and are considered a bad practice and legacy.
Async/Await and Promises
As the name suggests this model is based on promises. Promises represent an eventual computation (or failure). A function can return a promise, for example, the result of an HTTP request, and then caller functions can chain their logic to it. This is how concurrency is achieved in most popular languages. Java also has promised, but they are called Futures, however, only the CompletableFuture has the complete feature list of a Promise. Most operations in Java are blocking and Futures occupy the thread anyways.
Async/await is a syntax sugar over Promises. It saves you the tedious boilerplate you have to write for chaining, subscribing, and managing the promises. Usually, you can mark a function as async and its result is internally wrapped in a promise.
One huge problem you might have with async/await is the infamous colored function problem. Using async on a function essentially makes it non-blocking, but functions that are blocking (no async prefix) can’t call them unless they use await. You might ask, “So what? I will just make everything async and never use blocking functions”.. sure but you need one third-party library that is blocking and boom everything goes to hell. Furthermore, there are probably things in the language that are blocking by nature and you will be forced to deal with the function colors sooner or later. It has to be noted that in some languages like C# this is not the case and you have async/await without function color.
Coroutines (Continuation + routine)
When we talk about coroutines we don’t refer to Kotlin’s coroutines, they just stole the term.
Continuations are a special kind of function call. If function A calls function B and that is the last thing that A does then we can say that B is a continuation of A.
Routines (aka. Subroutines) are reusable pieces of code that are usually called multiple times during execution. Imagine them as an immutable set of instructions with input and output that you can call whenever you like.
Combining these terms we get CoRoutines. They are essentially suspendable tasks managed by the runtime, they form a tree-like structure of chain calls.
A Coroutine has a few key properties:
They can be suspended and resumed at any time
They are a data structure that can remember its state and stack trace
They can yield/give control to other coroutines (subroutines)
They must have isDone(), yield() and run() functions
Here is an example of a coroutine in JS, sorry to all hardcore Java readers :(
JavaScript has a yield mechanism. With it, you can create the so-called generators. To support this they pretty much-implemented coroutines into the language.
function *getNumbersGen() { let temp = 5; console.log("1"); yield 1; console.log("2"); yield 2; console.log("3"); yield 3; console.log("Temp " + temp);}
This is our simple generator. The ‘*’ marks the function as a generator, then the function can use yield. The yield keyword is used to pause and resume a generator function (same as suspend/run).
Now if we execute the following code, which takes numbers from the generator until it stops yielding them.
for (let n of getNumbersGen()) { console.log("Num " + n);}
We get
"1"
"Num 1"
"2"
"Num 2"
"3"
"Num 3"
"Temp 5"
Notice how the control is yielded between the two code blocks, first the generator prints the number then the loop prints it. Furthermore, we defined the temp variable at the beginning of the generator, and after this back and forth yielding the value of temp is still preserved and correctly printed. This generator implements everything it needs to be called a coroutine. It can be suspended, it can be resumed and it preserves its state. All of this is handled by the JS interpreter. This is great, we achieve concurrency without introducing any special words like async and await, we don’t have a colored function yet still operate on a single Thread.
Virtual Threads
The developers of Loom had many things to consider and multiple ways to implement Virtual Threads. I am glad they chose to go the coroutine way. The Thread class will stay the same and will use the same API. This makes migration seamless and switching to green threads is just a flag. However, this comes at a great cost. They had to go through every API of the language like Sockets and I/O and make it non-blocking in case it is running in a Virtual Thread. This is a huge change affecting the core APIs of the JDK. Furthermore, it has to be backward compatible and must not break existing logic. No wonder this took 5+ years to complete.
To switch to Virtual threads we don’t have to learn new things, we just have to unlearn a few.
Never pool Virtual Threads, they are cheap and it makes no sense
Stop using thread locals. They will work, but if you spawn millions of threads you will have memory problems. According to Ron Pressler: “Thread locals should have never been exposed to the end user and should have stayed as an internal implementation detail”.
An almost exhaustive list of advantages Virtual Threads have over platform ones
Context Switching becomes effectively free. They are managed by the JVM which means the JVM will be performing the context switch between threads.
Tail/Call optimization. They mention in the JEP that tail-call optimization is done on the threads. This can save a lot of memory for the stack, but it is still a work in progress
Cheap Start/Stop. When we stop the OS thread we have to make a syscall that will terminate the thread and then free the ram it occupied. When starting OS threads we again make a syscall. Starting and killing a green thread is only a matter of deleting the object and then letting the GC remove it.
Hard upper limits. As mentioned, the OS can handle so many threads. Even if the hardware improves we still won’t be able to keep up with the demand. Currently, you can spawn tens of millions of virtual threads (which should be enough for most cases)
A thread that performs a transaction behaves very differently than a Thread that does video processing. This is easy to overlook. Essentially what I am saying is that the OS and CPU have to be optimized for the general case. They have to be able to handle all kinds of tasks requested by the applications, so they can’t optimize for a particular use case. The JVM can optimize its threads for the concrete task of handling requests.
Resizable stack. Virtual threads live in the RAM. Their stack and metadata also live there. The Platform thread has to allocate a fixed stack size (With Java it’s 1MB) and that stack can’t be resized. This means you get stack overflow if you exceed it and waste memory if you don’t use it. Furthermore, the min required memory to bootstrap a Virtual Thread is around 200–300 bytes.
Working with Virtual Threads
Consider the following
for (int i = 0; i < 1_000_000; i++) { new Thread(() -> { try { Thread.sleep(1000); } catch (Exception e) { e.printStackTrace(); }}).start();}
Here we try to create 1 million regular threads, all the thread does is sleep 1 second and then die. Obviously, you will get an OutOfMemory error with this code, on my machine I was able to spawn 40k threads before running out of memory.
Now let’s try spawning virtual ones. To create a new virtual thread, we have to use Thread.startVirtualThread(runnable).
for (int i = 0; i < 1_000_000; i++) { Thread.startVirtualThread(() -> { try { Thread.sleep(1000); } catch (Exception e) { e.printStackTrace(); }});}
This code works just fine, I was able to spawn more than 20 million such threads on my machine. This is to be expected since the user mode threads are nothing more than an object in memory that the JVM manages.
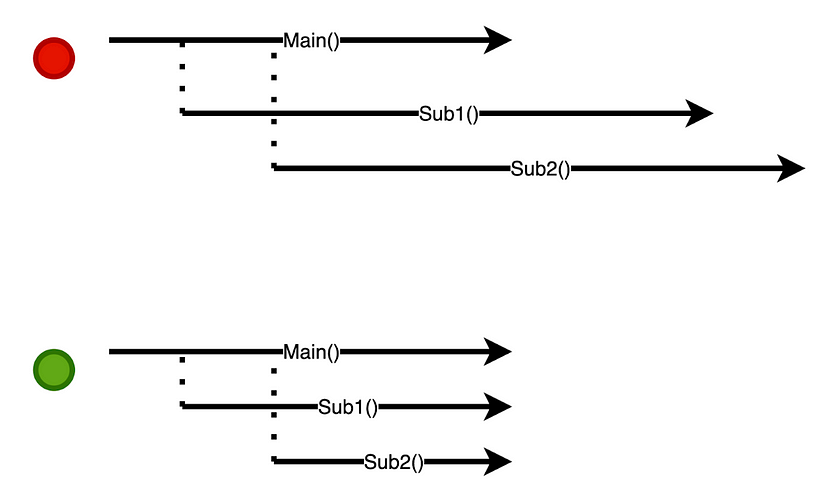
OK, let’s dive deeper, typically when we use threads we use them with thread pools. We will define a piece of blocking code that needs to be executed
We print the platform (carrier) thread that is running the code, then we make a 2-second HTTP call, and then we print the carrier thread again. Pretty simple.
Now let’s run this in parallel
try (ExecutorService executor = Executors.newFixedThreadPool(5)) { for (int i = 1; i <= 10; i++) { String taskName = "Task" + i; executor.execute(() -> someWork(taskName)); }}
We create our fixed-size thread pool with 5 threads and then submit 10 tasks that will just run the someWork method described earlier. Did you notice something else? The thread pool is in the try-with-resources block! This is a new addition to Java 19, try with resources now await for all threads to finish and we no longer have to use shutdown and awaitTermination when working with thread pools. Anyways the code above gives us the following output
Note how every task is executed by the same thread. (for example Task4 is executed and completed by Thread[#24,pool-1-thread-4,5,main])
This indicates that when the blocking call was made the thread was waiting and after 2 seconds resumed.
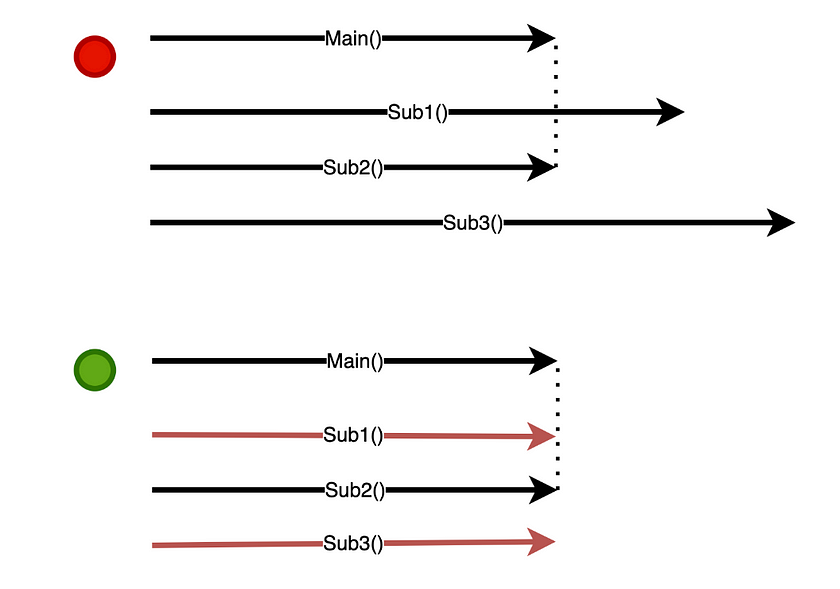
Now let’s convert this to User Mode threads. The code is the same, we just have to use Executors.newVirtualThreadPerTaskExecutor() which creates a new green thread every time a task is submitted to it.
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) { for (int i = 1; i <= 10; i++) { String taskName = "Task" + i; executor.execute(() -> someWork(taskName)); }}
Notice how now the task is executed by two threads, the first one executing the code before the blocking call and the second one after that. For example, Task5 is executed firstly by ForkJoinPool-1-worker-5 and then by ForkJoinPool-1-worker-1. This shows that we don’t block the carrier thread. Also, note that we are now using the fork-join pool. This pool has a size equal to the number of cores and is managed by the JVM. It is also used for things like parallel streams.
This is very similar to the JavaScript example we gave earlier. The threads are yielding control to each other, state preserved and then resumed, a true CoRoutine. The best part is that it is identical to a regular blocking code.
Server-Sent events
I wanted to give this as a cool use case for User Mode threads. If you are not familiar with SSE this is a good and more detailed explanation. Essentially we open an HTTP connection and never close it, then the server can push data to the client continuously. It is very lightweight and a lot cheaper than WebSockets. The problem is that to implement it we need a thread to be constantly running and sending events to the stream, if the thread dies we break the connection. You can already tell using platform threads here is not a good idea. Using Virtual threads we can do this in spring boot
SseEmitter is a special class from Spring MVC that implements the SSE protocol. What we do is create an endless loop (obviously not a production code) and send new data every 500ms to the client. Then any number of clients can subscribe to it
curl localhost:8080/api/v1/test/sse
and you will continuously receive events looking like this
data:SSE time -> 13:41:59.878294
id:f2059d56-d27e-461b-8f7c-1aa75b3aab64
event:Custom SSE
data:SSE time -> 13:42:00.383703
id:fdaac3bb-47aa-45b0-9382-549ff7549f08
event:Custom SSE
Having to manage virtual threads has its performance penalty. For applications with a smaller load, Threads might outperform virtual ones, simply because the context switching is low when there are few active clients. Furthermore, if your application is CPU intensive, for example, and performs a lot of mathematical computations, it makes no sense to use green threads because they will have to occupy the OS Thread when calculating anyways. Loom won’t make your applications faster it will just increase its throughput, and if throughput is not a problem then stick to platform threads. This blog does a good analysis and shows how Loom utilizes the threads, however in case you read it keep in mind that the author bashes on Loom for things it is not supposed to do in the first place (like fair thread scheduling).
Identify your bottlenecks. If are you using Postgres with a connection pool of 50, then spawning more than 50 threads (platform or non-platform) won’t make any difference.
For reference, you can check little’s law and this great article on the topic of choosing the optimal number of threads
Structured concurrency
Structured concurrency refers to the way we deal with the thread lifecycle. Currently, we have no way of stopping a thread that no longer needs to run since its result became obsolete. We can only send the interrupt signal which eventually will be consumed and the thread stops. This can waste both RAM and CPU cycles.
Let’s consider the following situations
All Tasks have to succeed if one fails there is no point in continuing
At least one task has to succeed if one succeeds no point in waiting for the rest
Deadlines. If execution is longer than a certain time we want to terminate everything
I have marked in red threads that need to be stopped immediately after a certain state is reached. With Loom we can do that, currently other than the special thread pool they will introduce we have no other way other than manually stopping the threads, but this JEP promises to bring more utilities to manage this.
These might seem like small optimizations and indeed they are insignificant with small applications or servers with low load. These things matter when you need to process millions of requests per day they can be a game changer and drastically increase your throughput in some situations.
Should you consider switching to Loom if you are using reactor frameworks
Reactor frameworks are great at dealing with the throughput problems of the application. What they do is essentially create abstract tasks (similar to coroutine) and wrap everything inside them. Then the reactor runtime manages these tasks. Sounds very similar to virtual threads but there are a few major problems
The language doesn’t support it natively, which leads to very complicated code (Flux/Mono)
The excellent Java Thread debugging that we talked about earlier is completely disregarded in favor of a centralized error handler that gives almost zero information about what happened. We have to rely mostly on logs
Once you go reactor style it’s very hard to go back, you will probably have to rewrite everything from scratch
I don’t like reactors (I also don’t like the actor model but it at least performs better and is easier to understand). I am a huge fan of blocking code and the thread-per-request model. They are readable and take full advantage of the Java language. These frameworks take that away and you need a really good reason to use them post-Loom.
Final words
I know this was a huge topic with lots of things to process. I hope it was useful. In case I didn’t explain something well feel free to comment and challenge me. I will also link all of the resources and further readings below so you can do your research if needed. Loom is still in the pre-release version, things might change, but one thing is certain, we will be getting Virtual Threads in JDK 19, the official release date, by the time I am writing this, is September 2022. Unfortunately, Java 19 is not an LTS and if you are working for one of those companies that only use LTS versions you will have to wait for Java 21 which should be released in September 2023.
Virtual threads are a lightweight implementation of Java threads, delivered as a preview feature in Java 19.
Virtual threads dramatically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications.
Virtual threads breathe new life into the familiar thread-per-request style of programming, allowing it to scale with near-optimal hardware utilization.
Virtual threads are fully compatible with the existing Thread API, so existing applications and libraries can support them with minimal change.
Virtual threads support the existing debugging and profiling interfaces, enabling easy troubleshooting, debugging, and profiling of virtual threads with existing tools and techniques.
Java 19 brings the first preview of virtual threads to the Java platform; this is the main deliverable of OpenJDKs Project Loom. This is one of the biggest changes to come to Java in a long time — and at the same time, is an almost imperceptible change. Virtual threads fundamentally change how the Java runtime interacts with the underlying operating system, eliminating significant impediments to scalability — but change relatively little about how we build and maintain concurrent programs. There is almost zero new API surface, and virtual threads behave almost exactly like the threads we already know. Indeed, to use virtual threads effectively, there is more unlearning than learning to be done.
Threads
Threads are foundational in Java. When we run a Java program, its main method is invoked as the first call frame of the "main" thread, which is created by the Java launcher. When one method calls another, the callee runs on the same thread as the caller, and where to return to is recorded on the threads stack. When a method uses local variables, they are stored in that methods call frame on the threads stack. When something goes wrong, we can reconstruct the context of how we got to the current point — a stack trace — by walking the current threads stack. Threads give us so many things we take for granted every day: sequential control flow, local variables, exception handling, single-step debugging, and profiling. Threads are also the basic unit of scheduling in Java programs; when a thread blocks waiting for a storage device, network connection, or a lock, the thread is descheduled so another thread can run on that CPU. Java was the first mainstream language to feature integrated support for thread-based concurrency, including a cross-platform memory model; threads are foundational to Javas model of concurrency.
Despite all this, threads often get a bad reputation, because most developers experience with threads is in trying to implement or debug shared-state concurrency. Indeed, shared-state concurrency — often referred to as “programming with threads and locks” — can be difficult. Unlike many other aspects of programming on the Java platform, the answers are not all to be found in the language specification or API documentation; writing safe, performant concurrent code that manages shared mutable state requires understanding subtle concepts like memory visibility, and a great deal of discipline. (If it were easier, the authors own Java Concurrency in Practice would not weigh in at almost 400 pages.)
Despite the legitimate apprehension that developers have when approaching concurrency, it is easy to forget that the other 99% of the time, threads are quietly and reliably making our lives much easier, giving us exception handling with informative stack traces, serviceability tools that let us observe what is going on in each thread, remote debugging, and the illusion of sequentiality that makes our code easier to reason about.
Platform threads
Java achieved write-once, run-anywhere for concurrent programs by ensuring that the language and APIs provided a complete, portable abstraction for threads, inter-thread coordination mechanisms, and a memory model that gives predictable semantics to the effects of threads on memory, that could be efficiently mapped to a number of different underlying implementations.
Most JVM implementations today implement Java threads as thin wrappers around operating system threads; well call these heavyweight, OS-managed threads platform threads. This isnt required — in fact, Javas threading model predates widespread OS support for threads — but because modern OSes now have good support for threads (in most OSes today, the thread is the basic unit of scheduling), there are good reasons to lean on the underlying platform threads. But this reliance on OS threads has a downside: because of how most OSes implement threads, thread creation is relatively expensive and resource-heavy. This implicitly places a practical limit on how many we can create, which in turn has consequences for how we use threads in our programs.
Operating systems typically allocate thread stacks as monolithic blocks of memory at thread creation time that cannot be resized later. This means that threads carry with them megabyte-scale chunks of memory to manage the native and Java call stacks. Stack size can be tuned both with command-line switches and Thread constructors, but tuning is risky in both directions. If stacks are overprovisioned, we will use even more memory; if they are underprovisioned, we risk StackOverflowException if the wrong code is called at the wrong time. We generally lean towards overprovisioning thread stacks as being the lesser of evils, but the result is a relatively low limit on how many concurrent threads we can have for a given amount of memory.
Limiting how many threads we can create is problematic because the simplest approach to building server applications is the thread-per-task approach: assign each incoming request to a single thread for the lifetime of the task.
Aligning the applications unit of concurrency (the task) with the platforms (the thread) in this way maximizes ease of development, debugging, and maintenance, leaning on all the benefits that threads invisibly give us, especially that all-important illusion of sequentiality. It usually requires little awareness of concurrency (other than configuring a thread pool for request handlers) because most requests are independent of each other. Unfortunately, as programs scale, this approach is on a collision course with the memory characteristics of platform threads. Thread-per-task scales well enough for moderate-scale applications — we can easily service 1000 concurrent requests — but we will not be able to service 1M concurrent requests using the same technique, even if the hardware has adequate CPU capacity and IO bandwidth.
Until now, Java developers who wanted to service large volumes of concurrent requests had several bad choices: constrain how code is written so it can use substantially smaller stack sizes (which usually means giving up on most third-party libraries), throw more hardware at the problem, or switch to an “async” or “reactive” style of programming. While the “async” model has had some popularity recently, it means programming in a highly constrained style which requires us to give up many of the benefits that threads give us, such as readable stack traces, debugging, and observability. Due to the design patterns employed by most async libraries, it also means giving up many of the benefits the Java language gives us as well, because async libraries essentially become rigid domain-specific languages that want to manage the entirety of the computation. This sacrifices many of the things that make programming in Java productive.
Virtual threads
Virtual threads are an alternative implementation of java.lang.Thread which store their stack frames in Javas garbage-collected heap rather than in monolithic blocks of memory allocated by the operating system. We dont have to guess how much stack space a thread might need, or make a one-size-fits-all estimate for all threads; the memory footprint for a virtual thread starts out at only a few hundred bytes, and is expanded and shrunk automatically as the call stack expands and shrinks.
The operating system only knows about platform threads, which remain the unit of scheduling. To run code in a virtual thread, the Java runtime arranges for it to run by mounting it on some platform thread, called a carrier thread. Mounting a virtual thread means temporarily copying the needed stack frames from the heap to the stack of the carrier thread, and borrowing the carriers stack while it is mounted.
When code running in a virtual thread would otherwise block for IO, locking, or other resource availability, it can be unmounted from the carrier thread, and any modified stack frames copied are back to the heap, freeing the carrier thread for something else (such as running another virtual thread.) Nearly all blocking points in the JDK have been adapted so that when encountering a blocking operation on a virtual thread, the virtual thread is unmounted from its carrier instead of blocking.
Mounting and unmounting a virtual thread on a carrier thread is an implementation detail that is entirely invisible to Java code. Java code cannot observe the identity of the current carrier (calling Thread::currentThread always returns the virtual thread); ThreadLocal values of the carrier thread are not visible to a mounted virtual thread; the stack frames of the carrier do not show up in exceptions or thread dumps for the virtual thread. During the virtual threads lifetime, it may run on many different carrier threads, but anything depending on thread identity, such as locking, will see a consistent picture of what thread it is running on.
Virtual threads are so-named because they share characteristics with virtual memory. With virtual memory, applications have the illusion that they have access to the entire memory address space, not limited by the available physical memory. The hardware completes this illusion by temporarily mapping plentiful virtual memory to scarce physical memory as needed, and when some other virtual page needs that physical memory, the old contents are first paged out to disk. Similarly, virtual threads are cheap and plentiful, and share the scarce and expensive platform threads as needed, and inactive virtual thread stacks are “paged” out to the heap.
Virtual threads have relatively little new API surface. There are several new methods for creating virtual threads (e.g., Thread::ofVirtual), but after creation, they are ordinary Thread objects and behave like the threads we already know. Existing APIs such as Thread::currentThread, ThreadLocal, interruption, stack walking, etc, work exactly the same on virtual threads as on platform threads, which means we can run existing code confidently on virtual threads.
The following example illustrates using virtual threads to concurrently fetch two URLs and aggregate their results as part of handling a request. It creates an ExecutorService that runs each task in a new virtual thread, submits two tasks to it, and waits for the results. ExecutorService has been retrofitted to implement AutoCloseable, so it can be used with try-with-resources, and the close method shuts down the executor and waits for tasks to complete.
void handle(Request request, Response response) { var url1 = ... var url2 = ... try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { var future1 = executor.submit(() -> fetchURL(url1)); var future2 = executor.submit(() -> fetchURL(url2)); response.send(future1.get() + future2.get()); } catch (ExecutionException | InterruptedException e) { response.fail(e); }}String fetchURL(URL url) throws IOException { try (var in = url.openStream()) { return new String(in.readAllBytes(), StandardCharsets.UTF_8); }}
On reading this code, we might initially worry it is somehow profligate to create threads for such short-lived activities or a thread pool for so few tasks, but this is just something we will have to unlearn — this code is a perfectly responsible use of virtual threads
Isnt this just “green threads”?
Java developers may recall that in the Java 1.0 days, some JVMs implemented threads using user-mode, or “green”, threads. Virtual threads bear a superficial similarity to green threads in that they are both managed by the JVM rather than the OS, but this is where the similarity ends. The green threads of the 90s still had large, monolithic stacks. They were very much a product of their time, when systems were single-core and OSes didnt have thread support at all. Virtual threads have more in common with the user-mode threads found in other languages, such as goroutines in Go or processes in Erlang — but have the advantage of being semantically identical to the threads we already have.
It’s about scalability
Despite the difference in creation costs, virtual threads are not faster than platform threads; we cant do any more computation with one virtual thread in one second than we can with a platform thread. Nor can we schedule any more actively running virtual threads than we can platform threads; both are limited by the number of available CPU cores. So, what is the benefit? Because they are so lightweight, we can have many more inactive virtual threads than we can with platform threads. At first, this may not sound like a big benefit at all! But “lots of inactive threads” actually describes the majority of server applications. Requests in server applications spend much more time doing network, file, or database I/O than computation. So if we run each task in its own thread, most of the time that thread will be blocked on I/O or other resource availability. Virtual threads allow IO-bound thread-per-task applications to scale better by removing the most common scaling bottleneck — the maximum number of threads — which in turn enables better hardware utilization. Virtual threads allow us to have the best of both worlds: a programming style that is in harmony with the platform rather than working against it, while allowing optimal hardware utilization.
For CPU-bound workloads, we already have tools to get to optimal CPU utilization, such as the fork-join framework and parallel streams. Virtual threads offer a complementary benefit to these. Parallel streams make it easier to scale CPU-bound workloads, but offer relatively little for IO-bound workloads; virtual threads offer a scalability benefit for IO-bound workloads, but relatively little for CPU-bound ones.
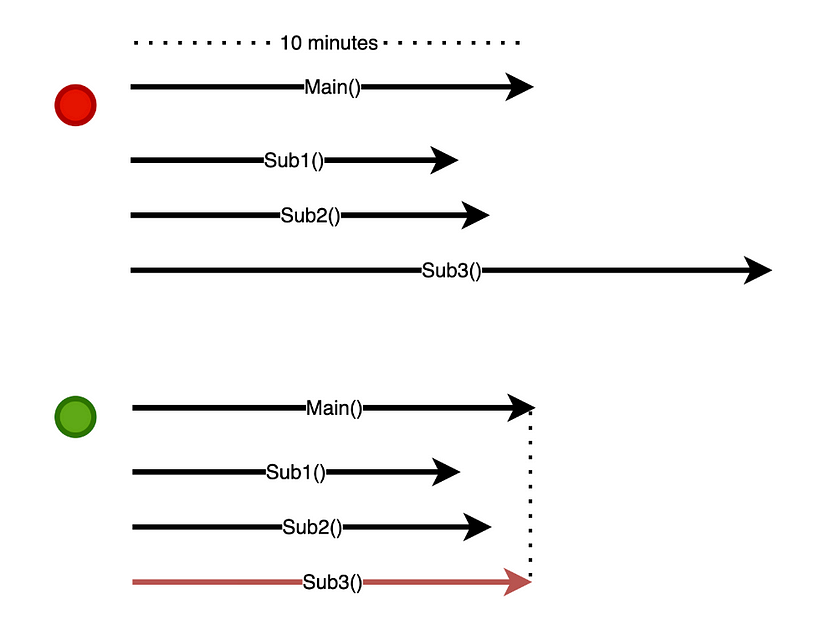
Littles Law
The scalability of a stable system is governed by Littles Law, which relates latency, concurrency, and throughput. If each request has a duration (or latency) of d, and we can perform N tasks concurrently, then throughput T is given by
T = N / d
Littles Law doesnt care about what portion of the time is spent “doing work” vs “waiting”, or whether the unit of concurrency is a thread, a CPU, an ATM machine, or a human bank teller. It just states that to scale up the throughput, we either have to proportionally scale down the latency or scale up the number of requests we can handle concurrently. When we hit the limit on concurrent threads, the throughput of the thread-per-task model is limited by Littles Law. Virtual threads address this in a graceful way by giving us more concurrent threads rather than asking us to change our programming model.
Virtual threads in action
Virtual threads do not replace platform threads; they are complementary. However, many server applications will choose virtual threads (often through the configuration of a framework) to achieve greater scalability.
The following example creates 100,000 virtual threads that simulate an IO-bound operation by sleeping for one second. It creates a virtual-thread-per-task executor and submits the tasks as lambdas.
On a modest desktop system with no special configuration options, running this program takes about 1.6 seconds in a cold start, and about 1.1 seconds after warmup. If we try running this program with a cached thread pool instead, depending on how much memory is available, it may well crash with OutOfMemoryError before all the tasks are submitted. And if we ran it with a fixed-sized thread pool with 1000 threads, it wont crash, but Littles Law accurately predicts it will take 100 seconds to complete.
Things to unlearn
Because virtual threads are threads and have little new API surface of their own, there is relatively little to learn in order to use virtual threads. But there are actually quite a few things we need to unlearn in order to use them effectively.
Everyone out of the pool
The biggest thing to unlearn is the patterns surrounding thread creation. Java 5 brought with it the java.util.concurrent package, including the ExecutorService framework, and Java developers have (correctly!) learned that it is generally far better to let ExecutorService manage and pool threads in a policy-driven manner than to create threads directly. But when it comes to virtual threads, pooling becomes an antipattern. (We dont have to give up using ExecutorService or the encapsulation of policy that it provides; we can use the new factory method Executors::newVirtualThreadPerTaskExecutor to get an ExecutorService that creates a new virtual thread per task.)
Because the initial footprint of virtual threads is so small, creating virtual threads is dramatically cheaper in both time and memory than creating platform threads — so much so, that our intuitions around thread creation need to be revisited. With platform threads, we are in the habit of pooling them, both to place a bound on resource utilization (because its easy to run out of memory otherwise), and to amortize the cost of thread startup over multiple requests. On the other hand, creating virtual threads is so cheap that it is actively a bad idea to pool them! We would gain little in terms of bounding memory usage, because the footprint is so small; it would take millions of virtual threads to use even 1G of memory. We also gain little in terms of amortizing creation overhead, because the creation cost is so small. And while it is easy to forget because pooling has historically been a forced move, it comes with its own problems, such as ThreadLocal pollution (where ThreadLocal values are left behind and accumulate in long-lived threads, causing memory leaks.)
If it is necessary to limit concurrency to bound consumption of some resource other than the threads themselves, such as database connections, we can use a Semaphore and have each virtual thread that needs the scarce resource acquire a permit.
Virtual threads are so lightweight that it is perfectly OK to create a virtual thread even for short-lived tasks, and counterproductive to try to reuse or recycle them. Indeed, virtual threads were designed with such short-lived tasks in mind, such as an HTTP fetch or a JDBC query.
Overuse of ThreadLocal
Libraries may also need to adjust their use of ThreadLocal in light of virtual threads. One of the ways in which ThreadLocal is sometimes used (some would say abused) is to cache resources that are expensive to allocate, not thread-safe, or simply to avoid repeated allocation of a commonly used object (e.g., ASM uses a ThreadLocal to maintain a per-thread char[] buffer, used for formatting operations.) When a system has a few hundred threads, the resource usage from such a pattern is usually not excessive, and it may be cheaper than reallocating each time it is needed. But the calculus changes dramatically with a few million threads that each only perform a single task, because there are potentially many more instances allocated and there is much less chance of each being reused. Using a ThreadLocal to amortize the creation cost of a costly resource across multiple tasks that may execute in the same thread is an ad-hoc form of pooling; if these things need to be pooled, they should be pooled explicitly.
What about Reactive?
A number of so-called “async” or “reactive” frameworks offer a path to fuller hardware utilization by asking developers to trade the thread-per-request style in favor of asynchronous IO, callbacks, and thread sharing. In such a model, when an activity needs to perform IO, it initiates an asynchronous operation which will invoke a callback when complete. The framework will invoke that callback on some thread, but not necessarily the same thread that initiated the operation. This means developers must break their logic down into alternating IO and computational steps which are stitched together into a sequential workflow. Because a request only uses a thread when it is actually computing something, the number of concurrent requests is not bounded by the number of threads, and so the limit on the number of threads is less likely to be the limiting factor in application throughput.
But, this scalability comes at a great cost — you often have to give up some of the fundamental features of the platform and ecosystem. In the thread-per-task model, if you want to do two things sequentially, you just do them sequentially. If you want to structure your workflow with loops, conditionals, or try-catch blocks, you just do that. But in the asynchronous style, you often cannot use the sequential composition, iteration, or other features the language gives you to structure the workflow; these must be done with API calls that simulate these constructs within the asynchronous framework. An API for simulating loops or conditionals will never be as flexible or familiar as the constructs built into the language. And if we are using libraries that perform blocking operations, and have not been adapted to work in the asynchronous style, we may not be able to use these either. So we may get scalability from this model, but we have to give up on using parts of the language and ecosystem to get it.
These frameworks also make us give up a number of the runtime features that make developing in Java easier. Because each stage of a request might execute in a different thread, and service threads may interleave computations belonging to different requests, the usual tools we use when things go wrong, such as stack traces, debuggers, and profilers, are much less helpful than in the thread-per-task model. This programming style is at odds with the Java Platform because the frameworks unit of concurrency — a stage of an asynchronous pipeline — is not the same as the platforms unit of concurrency. Virtual threads, on the other hand, allow us to gain the same throughput benefit without giving up key language and runtime features.
What about async/await?
A number of languages have embraced async methods (a form of stackless coroutines) as a means of managing blocking operations, which can be called either by other async methods or by ordinary methods using the await statement. Indeed, there was some popular call to add async/await to Java, as C# and Kotlin have.
Virtual threads offer some significant advantages that async/await does not. Virtual threads are not just syntactic sugar for an asynchronous framework, but an overhaul to the JDK libraries to be more “blocking-aware”. Without that, an errant call to a synchronous blocking method from an async task will still tie up a platform thread for the duration of the call. Merely making it syntactically easier to manage asynchronous operations does not offer any scalability benefit unless you find every blocking operation in your system and turn it into an async method.
A more serious problem with async/await is the “function color” problem, where methods are divided into two kinds — one designed for threads and another designed for async methods — and the two do not interoperate perfectly. This is a cumbersome programming model, often with significant duplication, and would require the new construct to be introduced into every layer of libraries, frameworks, and tooling in order to get a seamless result. Why would we implement yet another unit of concurrency — one that is only syntax-deep — which does not align with the threads we already have? This might be more attractive in another language, where language-runtime co-evolution was not an option, but fortunately we didnt have to make that choice.
API and platform changes
Virtual threads, and their related APIs, are a preview feature. This means that the --enable-preview flag is needed to enable virtual thread support.
Virtual threads are implementations of java.lang.Thread, so there is no new VirtualThread base type. However, the Thread API has been extended with some new API points for creating and inspecting threads. There are new factory methods for Thread::ofVirtual and Thread::ofPlatform, a new Thread.Builder class, and Thread::startVirtualThread to create a start a task on a virtual thread in one go. The existing thread constructors continue to work as before, but are only for creating platform threads.
There are a few behavioral differences between virtual and platform threads. Virtual threads are always daemon threads; the Thread::setDaemon method has no effect on them. Virtual threads always have priority Thread.NORM_PRIORITY which cannot be changed. Virtual threads do not support some (flawed) legacy mechanisms, such as ThreadGroup and the Thread methods stop, suspend, and remove. Thread::isVirtual will reveal whether a thread is virtual or not.
Unlike platform thread stacks, virtual threads can be reclaimed by the garbage collector if nothing else is keeping them alive. This means that if a virtual thread is blocked, say, on BlockingQueue::take, but neither the virtual thread nor the queue is reachable by any platform thread, then the thread and its stack can be garbage collected. (This is safe because in this case the virtual thread can never be interrupted or unblocked.)
Initially, carrier threads for virtual threads are threads in a ForkJoinPool that operates in FIFO mode. The size of this pool defaults to the number of available processors. In the future, there may be more options to create custom schedulers.
Preparing the JDK
While virtual threads are the primary deliverable of Project Loom, there was a number of improvements behind the scenes in the JDK to ensure that applications would have a good experience using virtual threads:
New socket implementations.JEP 353 (Reimplement the Legacy Socket API) and JEP 373 (Reimplement the Legacy DatagramSocket API) replaced the implementations of Socket, ServerSocket, and DatagramSocket to better support virtual threads (including making blocking methods interruptible in virtual threads.)
Virtual-thread-awareness. Nearly all blocking points in the JDK were made aware of virtual threads, and will unmount a virtual thread rather than blocking it.
Revisiting the use of ThreadLocal. Many uses of ThreadLocal in the JDK were revised in light of the expected changing usage patterns of threads.
Revisiting locking. Because acquiring an intrinsic lock (synchronized) currently pins a virtual thread to its carrier, critical intrinsic locks were replaced with ReentrantLock, which does not share this behavior. (The interaction between virtual threads and intrinsic locks is likely to be improved in the future.)
Improved thread dumps. Greater control over thread dumps, such as those produced by jcmd, is provided to filter out virtual threads, group related virtual threads together, or produce dumps in machine-readable formats that can be post-processed for better observability.
Related work
While virtual threads are the main course of Project Loom, there are several other Loom sub-projects that further enhance virtual threads. One is a simple framework for structured concurrency, which offers a powerful means to coordinate and manage cooperating groups of virtual threads. The other is extent local variables, which are similar to thread locals, but more suitable (and performant) for use in virtual threads. These will be the topics of upcoming articles.