CAP theorem
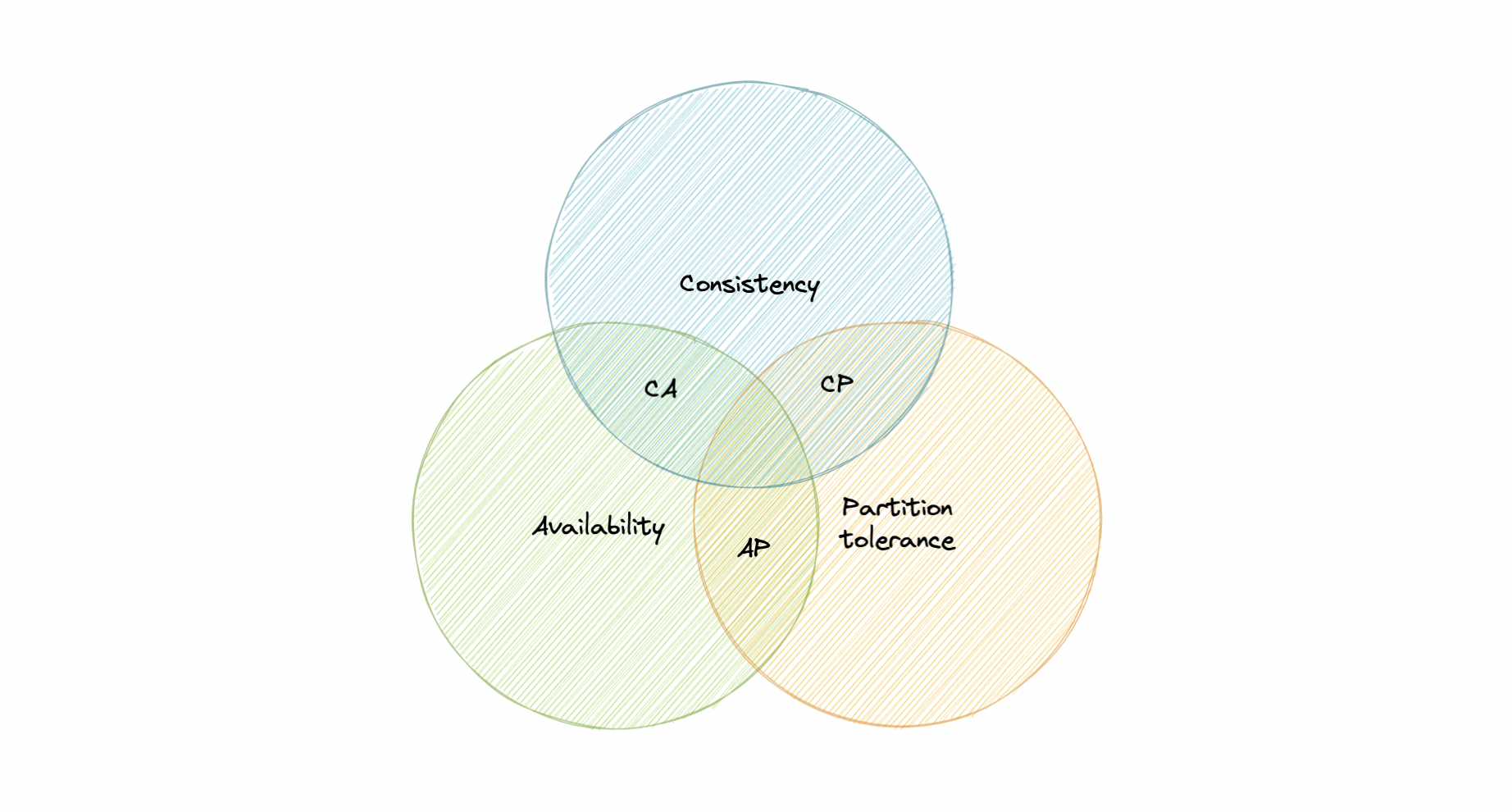
Let’s take a detailed look at the three distributed system characteristics to which the CAP theorem refers.
Consistency
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated across all the nodes in the system before the write is deemed “successful”.
Availability
Availability means that any client making a request for data gets a response, even if one or more nodes are down.
Partition tolerance
Partition tolerance means the system continues to work despite message loss or partial failure. A system that is partition-tolerant can sustain any amount of network failure that doesn’t result in a failure of the entire network. Data is sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
Consistency-Availability Tradeoff
We live in a physical world and can’t guarantee the stability of a network, so distributed databases must choose Partition Tolerance (P). This implies a tradeoff between Consistency (C) and Availability (A).
CA database
A CA database delivers consistency and availability across all nodes. It can’t do this if there is a partition between any two nodes in the system, and therefore can’t deliver fault tolerance.
Example: PostgreSQL, MariaDB.
CP database
A CP database delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any two nodes, the system has to shut down the non-consistent node until the partition is resolved.
Example: MongoDB, Apache HBase.
AP database
An AP database delivers availability and partition tolerance at the expense of consistency. When a partition occurs, all nodes remain available but those at the wrong end of a partition might return an older version of data than others. When the partition is resolved, the AP databases typically re-syncs the nodes to repair all inconsistencies in the system.
Example: Apache Cassandra, CouchDB.
Abstract
CAP refers to:
- Consistency: all nodes see the same data at the same time
- Availability: reads and writes always succeed
- Partition Tolerance: the system continues to operate despite arbitrary message loss or failure of part of the system
The CAP theorem states that a system can only focus on two letters.
In distributed system, failures of part of the system may occur due to network issues, which gives rise to system partitions ⇒ this leaves us either
APorCP, e.g. in case of network failure:
- sacrifice consistency: the node responds with old data
- sacrifice availability: the node only responds after the network is back and responds with the updated data
Zookeeper ensures the
CPsystem whereas Netflix Eureka ensures theAPsystem.
When you place an order on Amazon, your request is probably handled by one of the distributed computer nodes based on your location.
A distributed system is one where multiple nodes operating the same business logic are distributed on different computer nodes. If one node is down, others can still process the incoming requests. This ensures the efficiency and reliability for the application.
But there is a dilemma in a distributed system, which is known as ‘CAP Theorem’.
A brief elaboration on which letter means:
- C — Consistency: “all nodes see the same data at the same time.”
- A — Availability: “reads and writes always succeed.”
- P — Partition Tolerance: “the system continues to operate despite arbitrary message loss or failure of part of the system.”
The CAP theorem states that a system can only focus on two letters.
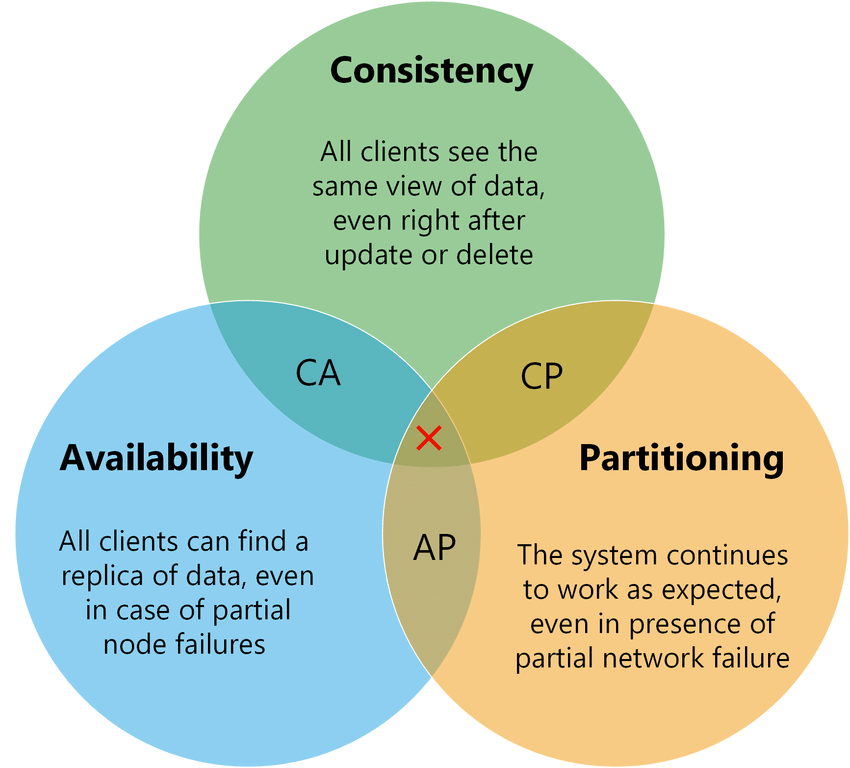
In a distributed system, failures of part of the system may occur due to network issues, which gives rise to system partitions. According to CAP Theorem, that leaves us either AP or CP.
How do we prove that?
Imagine there are two nodes in the network N1 and N2.
N1 and N2 contain two different services A and B, but both of them use the same database DB. Database system assigns two nodes DB1 and DB2 to N1 and N2 respectively.
Here we define:
consistency as the data consistency between DB1 and DB 2
availability as the responses from N1 and N2 upon outside requests
partition tolerance as accepting network failure between N1 and N2
Normally, if Service A updates its database DB1, the change will be synchronised to DB2 in N2 by the database system.
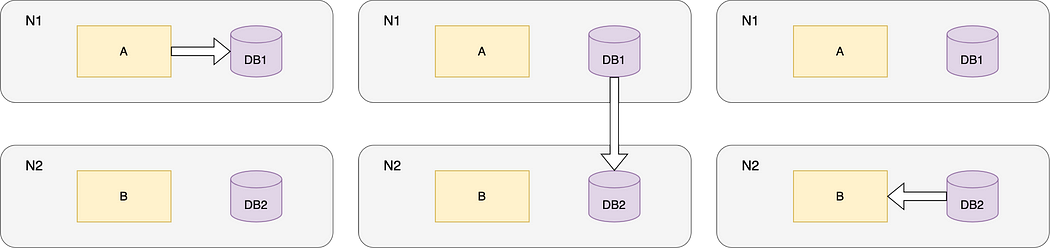
Normal Operation
Assume the network breaks down between N1 and N2 (P satisfied). When user sends request, N1 updates the data in DB1. But the updated data is not reflected in the DB2 of N2 due to the network failure.
What data should service B retrieve from DB2 then?
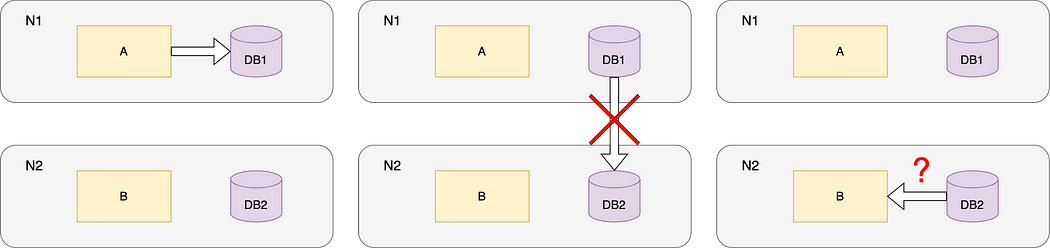
Network Failure
We only have two choices:
- Sacrifice consistency — N2 responds with old data from DB2.
- Sacrifice availability — N2 only responds after the network is back and responds with the updated data.
In real life, is there a CP system?

Zookeeper is a distributed, open-source coordination service for distributed applications. If there’s partitioning in the system, client’s requests will be timed out but the system ensures that all nodes will return the same data.
In real life, is there an AP system?
An AP system is Netflix Eureka.

Eureka helps to register and discover microservices. When there’s partitioning, the client can still access the system but the data might be old or new.
What’s in it for you?
Note that this article only talks about distributed systems. There is still another one — CA system, which often serves as a single server. One example is RDBMS.
Also note that CAP Theorem doesn’t mean that we have to give up the third letter totally. It is more of prioritising two over another based on the requirements.
All in all, there is no best structure. When we design a system, we should be aware of the business purposes of the application and make tradeoffs accordingly.
I hope you find this article helpful.