system design interview - url shortener
src: 👻 Lost from copy/paste-fu...
Let’s design a URL shortener, similar to services like Bitly, TinyURL.
What is a URL Shortener?
A URL shortener service creates an alias or a short URL for a long URL. Users are redirected to the original URL when they visit these short links.
For example, the following long URL can be changed to a shorter URL.
Long URL: https://karanpratapsingh.com/courses/system-design/url-shortener
Short URL: https://bit.ly/3I71d3o
Why do we need a URL shortener?
URL shortener saves space in general when we are sharing URLs. Users are also less likely to mistype shorter URLs. Moreover, we can also optimize links across devices, this allows us to track individual links.
Requirements
Our URL shortening system should meet the following requirements:
Functional requirements
- Given a URL, our service should generate a shorter and unique alias for it.
- Users should be redirected to the original URL when they visit the short link.
- Links should expire after a default timespan.
Non-functional requirements
- High availability with minimal latency.
- The system should be scalable and efficient.
Extended requirements
- Prevent abuse of services.
- Record analytics and metrics for redirections.
Estimation and Constraints
Let’s start with the estimation and constraints.
Note: Make sure to check any scale or traffic related assumptions with your interviewer.
Traffic
This will be a read-heavy system, so let’s assume a 100:1 read/write ratio with 100 million links generated per month.
Reads/Writes Per month
For reads per month:
Similarly for writes:
What would be Requests Per Second (RPS) for our system?
100 million requests per month translate into 40 requests per second.
And with a 100:1 read/write ratio, the number of redirections will be:
Bandwidth
Since we expect about 40 URLs every second, and if we assume each request is of size 500 bytes then the total incoming data for then write requests would be:
Similarly, for the read requests, since we expect about 4K redirections, the total outgoing data would be:
Storage
For storage, we will assume we store each link or record in our database for 10 years. Since we expect around 100M new requests every month, the total number of records we will need to store would be:
Like earlier, if we assume each stored recorded will be approximately 500 bytes. We will need around 6TB of storage:
Cache
For caching, we will follow the classic Pareto principle also known as the 80/20 rule. This means that 80% of the requests are for 20% of the data, so we can cache around 20% of our requests.
Since we get around 4K read or redirection requests each second. This translates into 350M requests per day.
Hence, we will need around 35GB of memory per day.
High-level estimate
Here is our high-level estimate:
| Type | Estimate |
|---|---|
| Writes (New URLs) | 40/s |
| Reads (Redirection) | 4K/s |
| Bandwidth (Incoming) | 20 KB/s |
| Bandwidth (Outgoing) | 2 MB/s |
| Storage (10 years) | 6 TB |
| Memory (Caching) | ~35 GB/day |
Data model design
Next, we will focus on the data model design. Here is our database schema:
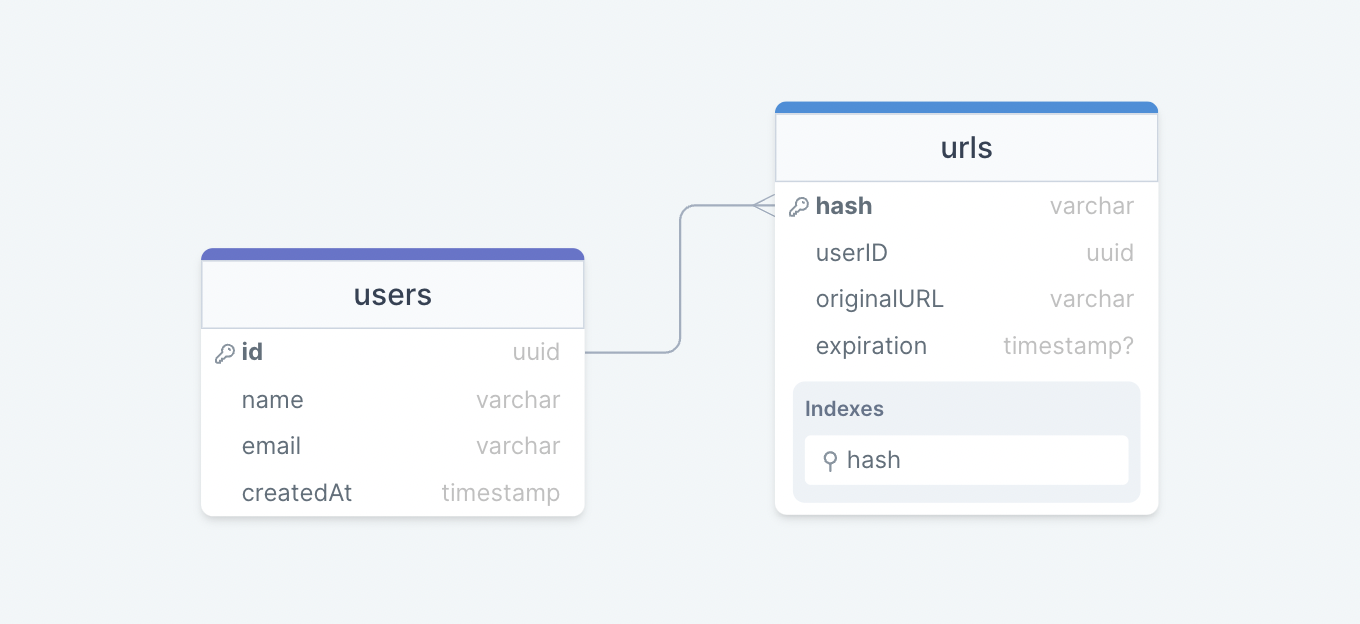
Initially, we can get started with just two tables:
users
Stores user’s details such as name, email, createdAt, etc.
urls
Contains the new short URL’s properties such as expiration, hash, originalURL, and userID of the user who created the short URL. We can also use the hash column as an index to improve the query performance.
What kind of database should we use?
Since the data is not strongly relational, NoSQL databases such as Amazon DynamoDB, Apache Cassandra, or MongoDB will be a better choice here, if we do decide to use an SQL database then we can use something like Azure SQL Database or Amazon RDS.
For more details, refer to SQL vs NoSQL.
API design
Let us do a basic API design for our services:
Create URL
This API should create a new short URL in our system given an original URL.
createURL(apiKey: string, originalURL: string, expiration?: Date): stringParameters
API Key (string): API key provided by the user.
Original Url (string): Original URL to be shortened.
Expiration (Date): Expiration date of the new URL (optional).
Returns
Short URL (string): New shortened URL.
Get URL
This API should retrieve the original URL from a given short URL.
getURL(apiKey: string, shortURL: string): stringParameters
API Key (string): API key provided by the user.
Short Url (string): Short URL mapped to the original URL.
Returns
Original URL (string): Original URL to be retrieved.
Delete URL
This API should delete a given shortURL from our system.
deleteURL(apiKey: string, shortURL: string): booleanParameters
API Key (string): API key provided by the user.
Short Url (string): Short URL to be deleted.
Returns
Result (boolean): Represents whether the operation was successful or not.
Why do we need an API key?
As you must’ve noticed, we’re using an API key to prevent abuse of our services. Using this API key we can limit the users to a certain number of requests per second or minute. This is quite a standard practice for developer APIs and should cover our extended requirement.
High-level design
Now let us do a high-level design of our system.
URL Encoding
Our system’s primary goal is to shorten a given URL, let’s look at different approaches:
Base62 Approach
In this approach, we can encode the original URL using Base62 which consists of the capital letters A-Z, the lower case letters a-z, and the numbers 0-9.
Where,
N: Number of characters in the generated URL.
So, if we want to generate a URL that is 7 characters long, we will generate ~3.5 trillion different URLs.
This is the simplest solution here, but it does not guarantee non-duplicate or collision-resistant keys.
MD5 Approach
The MD5 message-digest algorithm is a widely used hash function producing a 128-bit hash value (or 32 hexadecimal digits). We can use these 32 hexadecimal digits for generating 7 characters long URL.
However, this creates a new issue for us, which is duplication and collision. We can try to re-compute the hash until we find a unique one but that will increase the overhead of our systems. It’s better to look for more scalable approaches.
Counter Approach
In this approach, we will start with a single server which will maintain the count of the keys generated. Once our service receives a request, it can reach out to the counter which returns a unique number and increments the counter. When the next request comes the counter again returns the unique number and this goes on.
The problem with this approach is that it can quickly become a single point for failure. And if we run multiple instances of the counter we can have collision as it’s essentially a distributed system.
To solve this issue we can use a distributed system manager such as Zookeeper which can provide distributed synchronization. Zookeeper can maintain multiple ranges for our servers.
Once a server reaches its maximum range Zookeeper will assign an unused counter range to the new server. This approach can guarantee non-duplicate and collision-resistant URLs. Also, we can run multiple instances of Zookeeper to remove the single point of failure.
Key Generation Service (KGS)
As we discussed, generating a unique key at scale without duplication and collisions can be a bit of a challenge. To solve this problem, we can create a standalone Key Generation Service (KGS) that generates a unique key ahead of time and stores it in a separate database for later use. This approach can make things simple for us.
How to handle concurrent access?
Once the key is used, we can mark it in the database to make sure we don’t reuse it, however, if there are multiple server instances reading data concurrently, two or more servers might try to use the same key.
The easiest way to solve this would be to store keys in two tables. As soon as a key is used, we move it to a separate table with appropriate locking in place. Also, to improve reads, we can keep some of the keys in memory.
KGS database estimations
As per our discussion, we can generate up to ~56.8 billion unique 6 character long keys which will result in us having to store 300 GB of keys.
While 390 GB seems like a lot for this simple use case, it is important to remember this is for the entirety of our service lifetime and the size of the keys database would not increase like our main database.
Caching
Now, let’s talk about caching. As per our estimations, we will require around ~35 GB of memory per day to cache 20% of the incoming requests to our services. For this use case, we can use Redis or Memcached servers alongside our API server.
For more details, refer to caching.
Design
Now that we have identified some core components, let’s do the first draft of our system design.
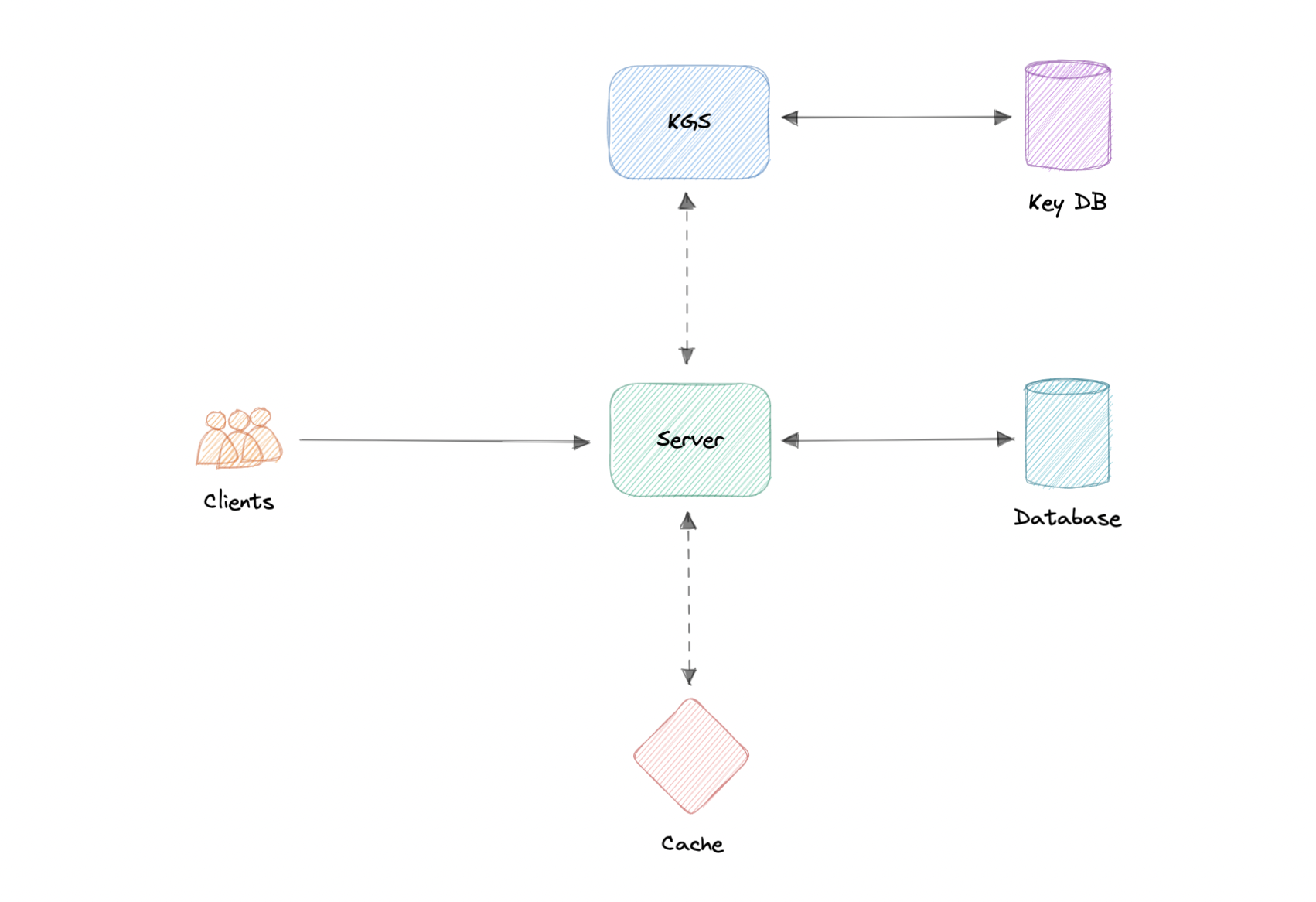
Here’s how it works:
Creating a new URL
- When a user creates a new URL, our API server requests a new unique key from the Key Generation Service (KGS).
- Key Generation Service provides a unique key to the API server and marks the key as used.
- API server writes the new URL entry to the database and cache.
- Our service returns an HTTP 201 (Created) response to the user.
Accessing a URL
- When a client navigates to a certain short URL, the request is sent to the API servers.
- The request first hits the cache, and if the entry is not found there then it is retrieved from the database and an HTTP 301 (Redirect) is issued to the original URL.
- If the key is still not found in the database, an HTTP 404 (Not found) error is sent to the user.
Detailed design
It’s time to discuss the finer details of our design.
Data Partitioning
To scale out our databases we will need to partition our data. Horizontal partitioning (aka Sharding) can be a good first step. We can use partitions schemes such as:
- Hash-Based Partitioning
- List-Based Partitioning
- Range Based Partitioning
- Composite Partitioning
The above approaches can still cause uneven data and load distribution, we can solve this using Consistent hashing.
For more details, refer to Sharding and Consistent Hashing.
Database cleanup
This is more of a maintenance step for our services and depends on whether we keep the expired entries or remove them. If we do decide to remove expired entries, we can approach this in two different ways:
Active cleanup
In active cleanup, we will run a separate cleanup service which will periodically remove expired links from our storage and cache. This will be a very lightweight service like a cron job.
Passive cleanup
For passive cleanup, we can remove the entry when a user tries to access an expired link. This can ensure a lazy cleanup of our database and cache.
Cache
Now let us talk about caching.
Which cache eviction policy to use?
As we discussed before, we can use solutions like Redis or Memcached and cache 20% of the daily traffic but what kind of cache eviction policy would best fit our needs?
Least Recently Used (LRU) can be a good policy for our system. In this policy, we discard the least recently used key first.
How to handle cache miss?
Whenever there is a cache miss, our servers can hit the database directly and update the cache with the new entries.
Metrics and Analytics
Recording analytics and metrics is one of our extended requirements. We can store and update metadata like visitor’s country, platform, the number of views, etc alongside the URL entry in our database.
Security
For security, we can introduce private URLs and authorization. A separate table can be used to store user ids that have permission to access a specific URL. If a user does not have proper permissions, we can return an HTTP 401 (Unauthorized) error.
We can also use an API Gateway as they can support capabilities like authorization, rate limiting, and load balancing out of the box.
Identify and resolve bottlenecks
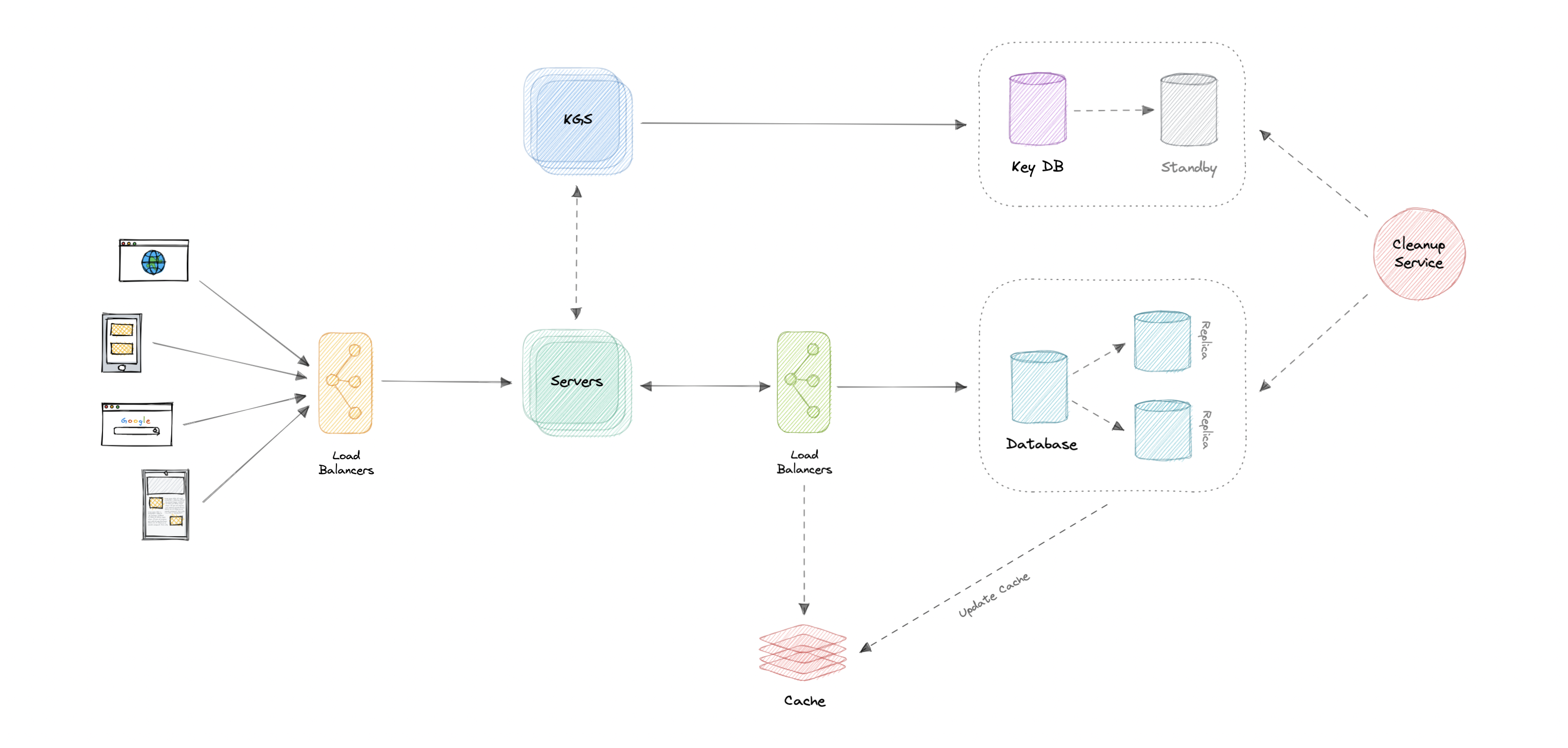
Let us identify and resolve bottlenecks such as single points of failure in our design:
- “What if the API service or Key Generation Service crashes?”
- “How will we distribute our traffic between our components?”
- “How can we reduce the load on our database?”
- “What if the key database used by KGS fails?”
- “How to improve the availability of our cache?”
To make our system more resilient we can do the following:
- Running multiple instances of our Servers and Key Generation Service.
- Introducing load balancers between clients, servers, databases, and cache servers.
- Using multiple read replicas for our database as it’s a read-heavy system.
- Standby replica for our key database in case it fails.
- Multiple instances and replicas for our distributed cache.